
从10-K -提取SIC,CIK,创建元数据表
从10-K -提取SIC,CIK,创建元数据表
提问于 2017-04-17 11:31:40
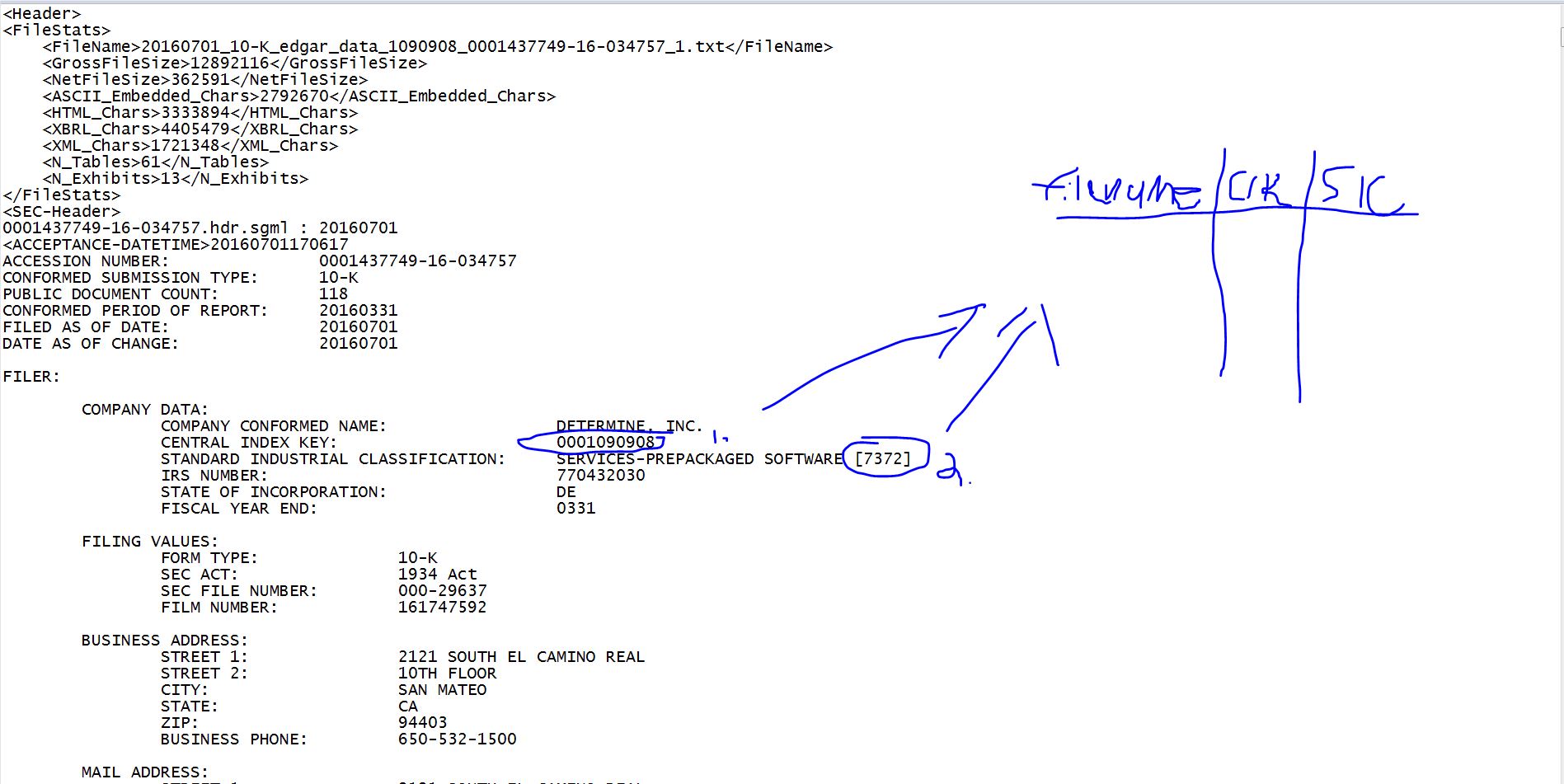
我和埃德加的10 Ks一起工作。为了帮助文件管理和数据分析,我想创建一个表,其中包含每个文件的路径、公司提交的CIK编号(这是SEC颁发的唯一ID )以及它所属的SIC行业代码。下面是我想要做的事。
我想要提取的两件东西列在每个文档的顶部。CIK #始终是在短语“中央索引键:”之后列出的一个数字。碳化硅#始终是“标准工业分类”之后括号内的一个数字,然后是对该特定行业的描述。
这在所有文件中是一致的。
去做:
- 循环遍历文件:提取文件路径、CIK和SIC数字--注意,每个文档只返回一次,每个结果都是有序的,所以字段之间的记录是对齐的。
- 将这些字段合并在一起--我猜最好的方法是将每个字段提取到各自的单独列表中,然后合并,也许合并成一个Pandas dataframe?
最终,我将使用这个表来帮助我在SIC行业之间划分数据。
谢谢你看一看。如果我能提供更多的文件,请告诉我。
回答 1
Stack Overflow用户
发布于 2019-02-01 03:57:19
下面是我为做类似事情而写的一些代码。您可以将结果输出到CSV文件中。作为第一步,您需要遍历该文件夹并获得所有10-K的列表并对其进行迭代。
year_end = ""
sic = ""
with open(txtfile, 'r', encoding='utf-8', errors='replace') as rawfile:
for cnt, line in enumerate(rawfile):
#print(line)
if "CONFORMED PERIOD OF REPORT" in line:
year_end = line[-9:-1]
#print(year_end)
if "STANDARD INDUSTRIAL CLASSIFICATION" in line:
match = re.search(r"\d{4}", line)
if match:
sic = match.group(0)
#print(sic)
#print(sic)
if (year_end and sic) or cnt > 100:
#print(year_end, sic)
break页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/43450621
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号