
向数据帧中添加百分比列
向数据帧中添加百分比列
提问于 2017-04-06 21:50:05
我有一只熊猫df如下所示:
User Purchase_Count Location_Count
1 2 3
2 10 5
3 5 1
4 20 4
5 2 3
6 2 3
7 10 5如何添加计算总条目的坐标对(Purchse_Count[i], Location_Count[i]) %的列。因此,例如,我希望df看起来像:
User Purchase_Count Location_Count %
1 2 3 42.85
2 10 5 28.57
3 5 1 14.28
4 20 4 14.28
5 2 3 42.85
6 2 3 42.85
7 10 5 28.57回答 2
Stack Overflow用户
回答已采纳
发布于 2017-04-06 21:57:13
pandas解决方案是使用groupby,然后使用transform
In [43]: df
Out[43]:
User Purchase_Count Location_Count
0 1 2 3
1 2 10 5
2 3 5 1
3 4 20 4
4 5 2 3
5 6 2 3
6 7 10 5
In [44]: total = len(df)
In [45]: df['percentage'] = df.groupby(['Purchase_Count', 'Location_Count']).transform(lambda r: r.count()/total)
In [46]: df
Out[46]:
User Purchase_Count Location_Count percentage
0 1 2 3 0.428571
1 2 10 5 0.285714
2 3 5 1 0.142857
3 4 20 4 0.142857
4 5 2 3 0.428571
5 6 2 3 0.428571
6 7 10 5 0.285714编辑以提高可读性
In [53]: df['percentage'] = (df.groupby(['Purchase_Count', 'Location_Count'])
...: .transform(lambda r: r.count()/total))
In [54]: df
Out[54]:
User Purchase_Count Location_Count percentage
0 1 2 3 0.428571
1 2 10 5 0.285714
2 3 5 1 0.142857
3 4 20 4 0.142857
4 5 2 3 0.428571
5 6 2 3 0.428571
6 7 10 5 0.285714编辑:
正如@piRSquared所建议的那样,您可以使用:
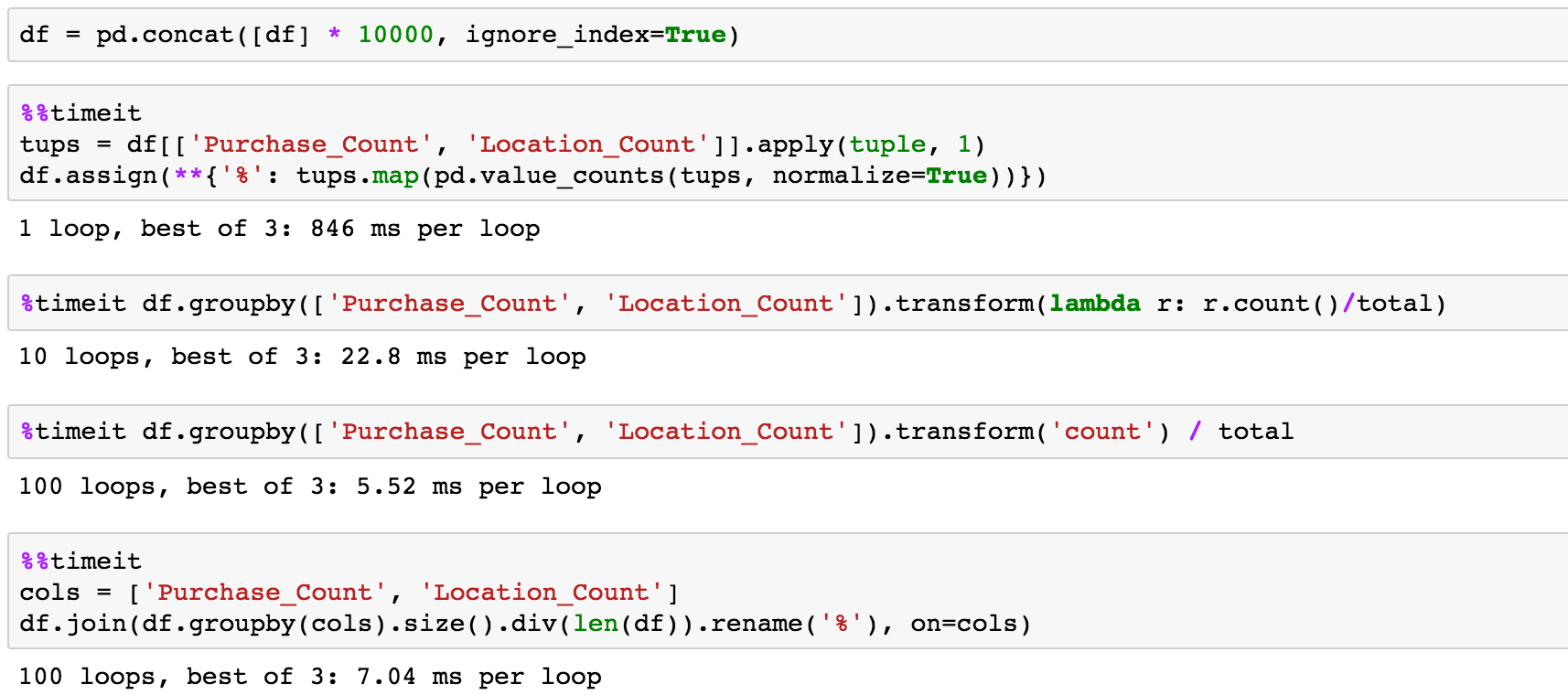
df.groupby(['Purchase_Count', 'Location_Count']).transform('count') / total相反,初步测试表明它的速度要快得多。
Stack Overflow用户
发布于 2017-04-06 21:58:33
将groupby与size和join结合使用
cols = ['Purchase_Count', 'Location_Count']
df.join(df.groupby(cols).size().div(len(df)).rename('%'), on=cols)
User Purchase_Count Location_Count %
0 1 2 3 0.428571
1 2 10 5 0.285714
2 3 5 1 0.142857
3 4 20 4 0.142857
4 5 2 3 0.428571
5 6 2 3 0.428571
6 7 10 5 0.285714旧答案
在元组上使用pd.value_counts
tups = df[['Purchase_Count', 'Location_Count']].apply(tuple, 1)
df.assign(**{'%': tups.map(pd.value_counts(tups, normalize=True))})
User Purchase_Count Location_Count %
0 1 2 3 0.428571
1 2 10 5 0.285714
2 3 5 1 0.142857
3 4 20 4 0.142857
4 5 2 3 0.428571
5 6 2 3 0.428571
6 7 10 5 0.285714定时
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/43266354
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号