
Neo4j - Java堆空间。查询或设置错误?
我对neo4j有个问题。我不知道问题是我的问题还是别的什么。
Intro
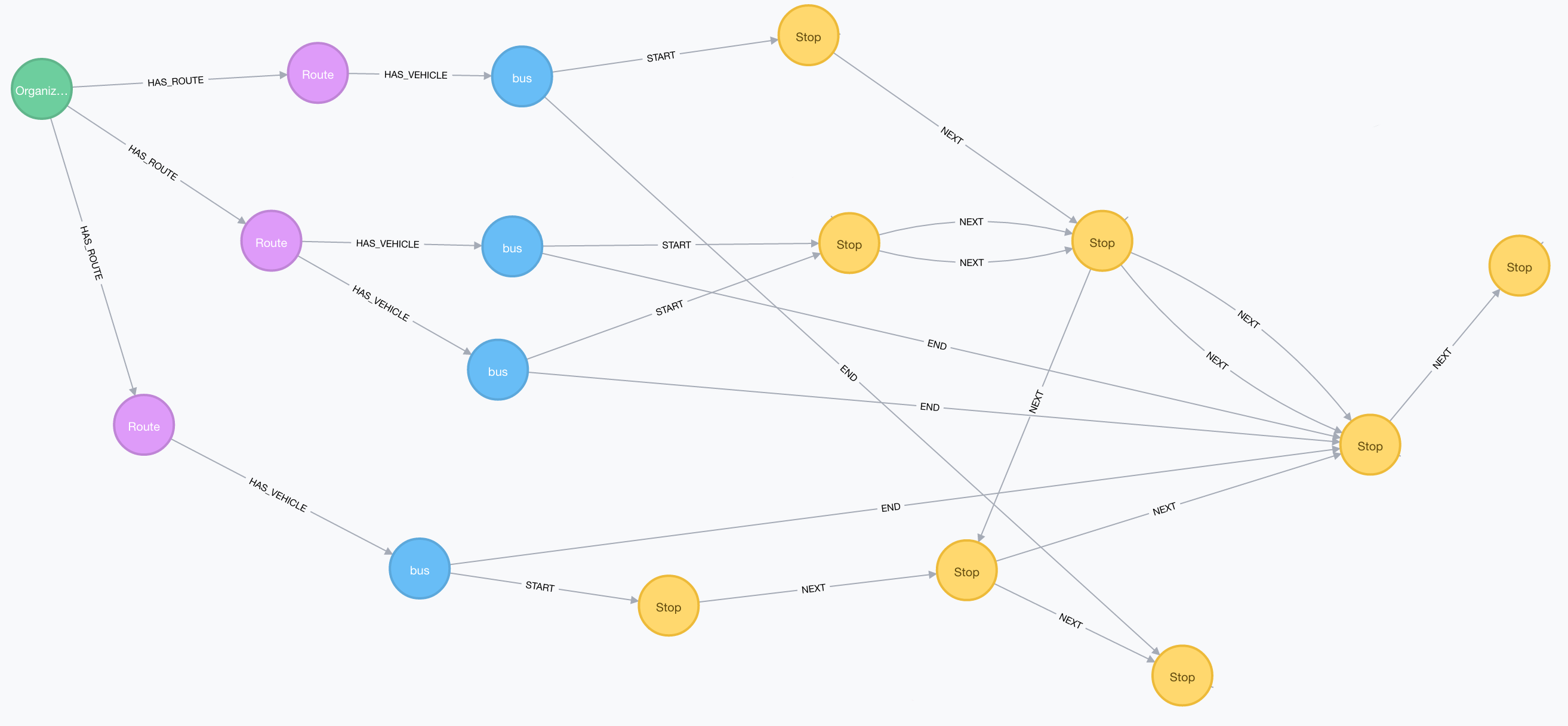
我必须建立一个存储公交/火车线路的应用程序。这是我的模式:
节点
- 组织:有路线/巴士等的公司。
- 路线:像巴黎-柏林这样的巴士路线。
- 车辆(本例中为公共汽车):具有独特牌照的财政公共汽车。
- 停止:在地图上指向纬度和经度。
重要关系
- 接下来:这是一段非常重要的关系。
接下来的关系包含以下属性:
- startHour
- startMinutes
- endHour
- endMinutes
- dayOfWeek (从0到6- Sun,Mon等)
- vehicleId
问题
我的问题是:
MATCH (s1:Stop {id: {departureStopId}}), (s2:Stop {id: {arrivalStopId}})
OPTIONAL MATCH (s1)-[nexts:NEXT*]->(s2)
WHERE ALL(i in nexts WHERE toInt(i.dayOfWeek) = {dayOfWeek} AND toInt(i.startHour) >= {hour})
RETURN nexts
LIMIT 10例如:我希望找到所有dayOfWeek为Sunday (0)且属性startHour > 11的关系
之后,我通常在nodejs后端解析和验证最终对象。
这在我刚开始的时候就起作用了。有着1k的关系。现在我有10k的关系,我的查询有一个超时问题,或者查询在30多个小时内就解决了。时间太多了..。我不知道怎么解决这个问题。我将neo4j与docker一起使用,并尝试读取设置文档,但我不知道Java是如何工作的。
你们能帮我吗?
更新
谢谢大家!现在我用"allShortestPaths“来解决问题,但我想我会重新命名所有的关系(就像Michael说的那样)。
回答 3
Stack Overflow用户
发布于 2017-04-02 15:44:25
你试过:
MATCH p=allShortestPaths((s1:Stop {id: {departureStopId}})-[:NEXT*]-> (s2:Stop {id: {arrivalStopId}}) )
WHERE ALL(i in RELS(p) WHERE toInt(i.dayOfWeek) = {dayOfWeek} AND toInt(i.startHour) >= {hour})
RETURN rels(p) as nexts
LIMIT 10这应该使用快速最短路径算法,因为:
根据需要评估的谓词,在Cypher中规划最短路径可以导致不同的查询计划。在内部,如果可以在搜索路径时评估谓词,Neo4j将使用快速双向宽度优先搜索算法。
有关更多详细信息,请参阅algorithm。
Stack Overflow用户
发布于 2017-04-02 13:19:09
你能分享你的个人资料吗。
我想你对:Stop(id)有一个限制
我会使用最短路径或dijkstra与成本,而不是可选的匹配。可选匹配将尝试找到所有这样的路径,其中有数亿,并过滤,因为他们走。
按照一周中的一天( .e.g :NEXT_MO, :NEXT_THU )将您的:NEXT_MO, :NEXT_THU关系分组可能是有意义的,因此您只需要查看1/7的数据。
Stack Overflow用户
发布于 2017-04-02 12:16:44
这不是设置,而是查询必须访问图中的每个节点才能满足查询的事实。
当必须使用表扫描而不是索引时,这个问题将在关系数据库中显示出来。
我认为解决方案是增加几个小时的桶,就像你已经数天了一样。如果你必须有几分钟的时间,那就制造96个15分钟的桶来覆盖一天。这将为查询优化器提供最佳机会。
https://stackoverflow.com/questions/43168152
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号