
加快Python中点是否处于形状的顺序检查
加快Python中点是否处于形状的顺序检查
提问于 2017-03-22 07:04:36
我有一个连续的代码,无论在我的DataFrame中找到的每一对笛卡尔坐标是否属于某些几何封闭的区域。但这是相当缓慢的,我怀疑,因为它没有矢量化。下面是一个示例:
from matplotlib.patches import Rectangle
r1 = Rectangle((0,0), 10, 10)
r2 = Rectangle((50,50), 10, 10)
df = pd.DataFrame([[1,2],[-1,5], [51,52]], columns=['x', 'y'])
for j in range(df.shape[0]):
coordinates = df.x.iloc[j], df.y.iloc[j]
if r1.contains_point(coordinates):
df['location'].iloc[j] = 0
else r2.contains_point(coordinates):
df['location'].iloc[j] = 1有人能提出提速的方法吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-03-22 07:53:03
最好是将矩形块转换成一个数组,并在推导出它们的分布程度之后再对其进行处理。
def seqcheck_vect(df):
xy = df[["x", "y"]].values
e1 = np.asarray(rec1.get_extents())
e2 = np.asarray(rec2.get_extents())
r1m1, r1m2 = np.min(e1), np.max(e1)
r2m1, r2m2 = np.min(e2), np.max(e2)
out = np.where(((xy >= r1m1) & (xy <= r1m2)).all(axis=1), 0,
np.where(((xy >= r2m1) & (xy <= r2m2)).all(axis=1), 1, np.nan))
return df.assign(location=out)对于给定的样本,函数输出如下:
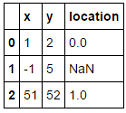
基准:
def loopy_version(df):
for j in range(df.shape[0]):
coordinates = df.x.iloc[j], df.y.iloc[j]
if rec1.contains_point(coordinates):
df.loc[j, "location"] = 0
elif rec2.contains_point(coordinates):
df.loc[j, "location"] = 1
else:
pass
return df10K行的DF :上的测试
np.random.seed(42)
df = pd.DataFrame(np.random.randint(0, 100, (10000,2)), columns=list("xy"))
# check if both give same outcome
loopy_version(df).equals(seqcheck_vect(df))
True
%timeit loopy_version(df)
1 loop, best of 3: 3.8 s per loop
%timeit seqcheck_vect(df)
1000 loops, best of 3: 1.73 ms per loop因此,矢量化方法的速度大约是空想方法的2200倍。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/42944841
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号