
将数据抓取到URL
将数据抓取到URL
提问于 2017-03-19 05:52:24
我很想对所有正在放映并返回imdb评级的电影进行http://www.regmovies.com/Theatres/Theatre-Folder/Regal-Meridian-16-1082扫描。
在刮伤外壳中,我设置了以下值:
fetch('http://www.regmovies.com/Theatres/Theatre-Folder/Regal-Meridian-16-1082')
response.xpath('//*[@id="content"]/div/div/div[2]/div[1]/div[7]/div[2]/div[1]/div/div[1]/h3/text()').extract()
返回的值是空的,>>> [],这是构建我的蜘蛛的最后一部分。
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-03-19 06:12:13
本页面使用JavaScipe获取数据,您可以在Chrome的NetWork选项卡中找到数据URL:
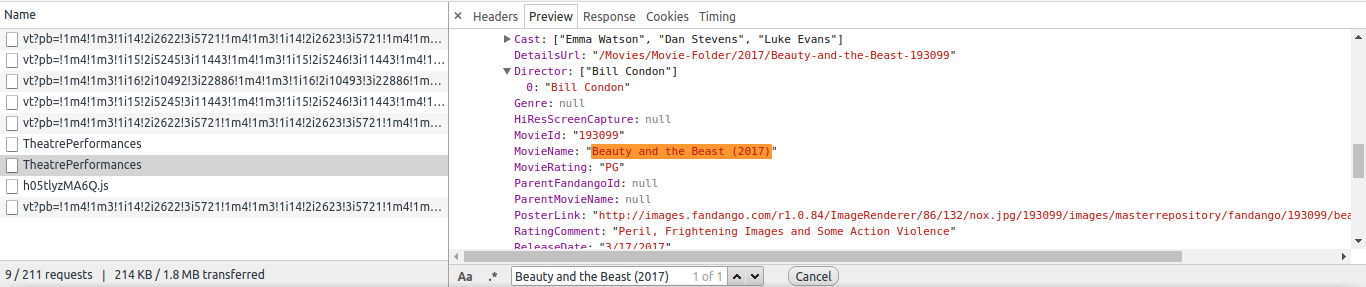
您应该将Scrapy Post数据用于此URL:
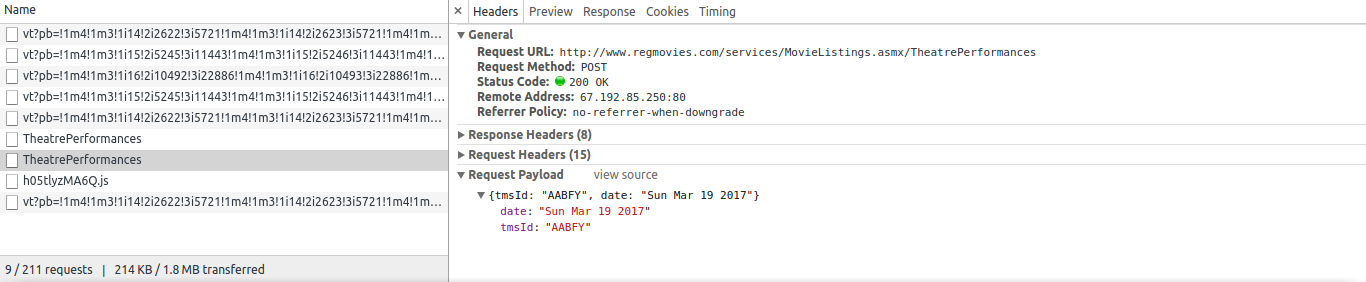
In [9]: from scrapy.http import Request
In [10]: r = Request(url='http://www.regmovies.com/services/MovieListings.asmx/TheatrePerformances',
...: method='POST',
...: body='{"tmsId":"AABFY","date":"Sun Mar 19 2017"}',
...: headers={'Content-Type':'application/json', 'User-Agent':'Mozilla/5.0'})
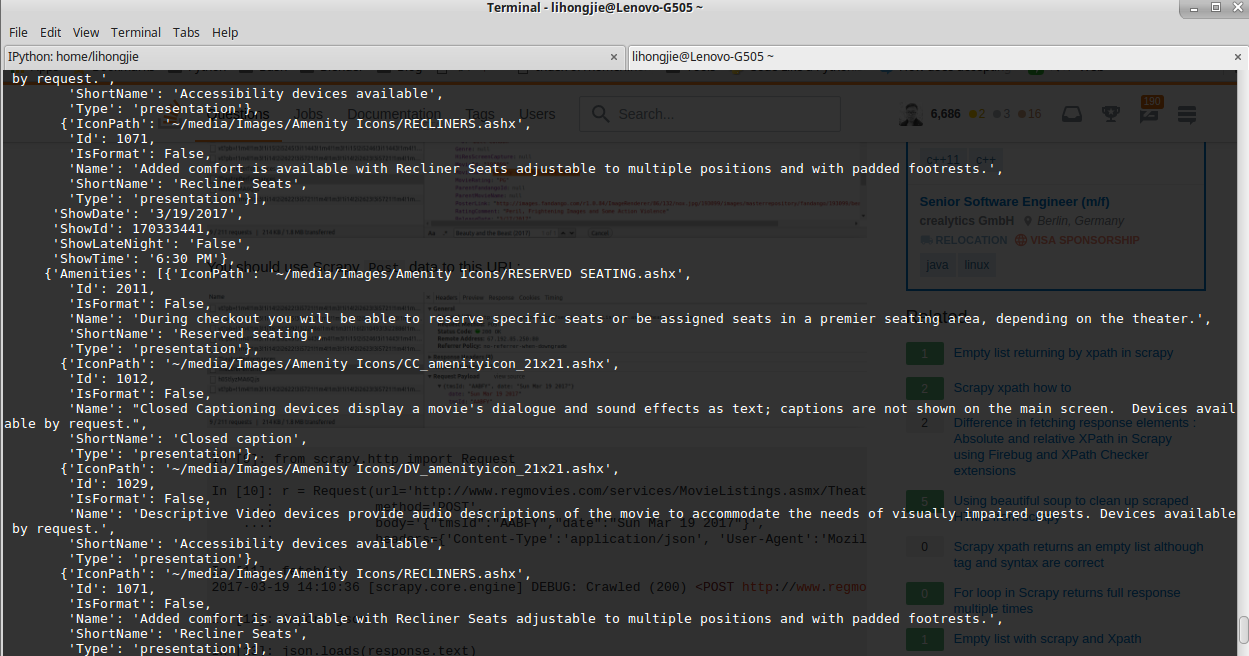
In [11]: fetch(r)
2017-03-19 14:10:36 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.regmovies.com/services/MovieListings.asmx/TheatrePerformances> (referer: None)
In [12]: import json
In [13]: json.loads(response.text) 退出:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/42883382
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号