
如何使用Python/Pandas度量预测的准确性?
我已经使用Elo和Glicko评分系统以及比赛的结果来生成球员的评分。在每一场比赛之前,我可以根据每个球员各自的评分,为他们生成一个期望(浮动在0到1之间)。我想检验一下这一预期有多准确,原因有二:
- 比较不同评级系统
- 调优用于计算评级的变量(如Elo中的kfactor )
国际象棋有几个值得注意的区别:
- 可能的结果是胜利(我把它当作1.0),失败(0.0),偶尔(<5%)平局(每张0.5)。每一场比赛都被评分,而不是像国际象棋那样的系列赛。
- 球员有更少的比赛--很多少于10,很少超过25,最大值是75。
考虑到适当的函数是“相关性”,我尝试创建一个DataFrame,其中包含一个列中的预测(在0,1之间浮动),在另一个列中包含预测结果(10.5\x\0),并使用corr(),但是根据输出,我不确定这是否正确。
如果我创建一个DataFrame,其中只包含匹配中的第一个玩家的期望和结果(结果总是为1.0或0.5,因为由于我的数据源,输家永远不会首先显示),corr()返回的值很低:< 0.05。但是,如果我为每一场比赛创建了一个有两行的序列,并且包含了每个玩家的期望和结果(或者,随机选择添加哪个玩家,结果将是0、0.5或1),那么corr()就会高得多:~0.15到0.30。我不明白这会有什么不同,这让我怀疑我是在滥用这个函数,还是完全使用了错误的函数。
如果有用的话,下面是一些真实的(不是随机的)示例数据:http://pastebin.com/eUzAdNij
回答 2
Stack Overflow用户
发布于 2017-03-20 20:42:50
实际上,你所观察到的是完全有道理的。如果没有平局,而且你总是在第一排显示胜利者的期望,那么第二排根本就没有关联!因为无论期望有多大或多小,第二行中的数字总是1.0,也就是说,它根本不依赖于第一行中的数字。
由于抽签的百分比很低(绘图可能与0.5周围的值相关),您仍然可以观察到一个小的相关性。
也许相关性并不是这里预测准确性的最佳衡量标准。
问题之一是,Elo并不是预测单个结果,而是预测预期的点数。至少有一个未知的因素:抽签的概率。你必须在你的模型中加入更多关于抽签概率的知识。这个概率取决于球员之间的力量差异:差距越大,平局的机会就越小。人们可以尝试以下方法:
- 将预期的点数映射到预期的结果,例如
0...0.4表示损失,0.4..0.6-一个平局和0.6...1.0-一个胜利,看看有多少结果是正确预测的。 - 对于一个玩家和一堆游戏来说,精确性的衡量标准是球员的
|predicted_score-score|/number_of_games平均值。差别越小越好。 - 一种贝叶斯方法:如果一个游戏的预测点数是
x,而预测器的分数是x(如果游戏赢了,则是1-x)(也许您必须跳过平局,或者将其作为(1-x)*x/4得分-因此0.5的预测将得到1的分数)。预测器在所有游戏中的总分将是单个游戏分数的乘积。分数越大越好。
Stack Overflow用户
发布于 2017-03-22 19:42:25
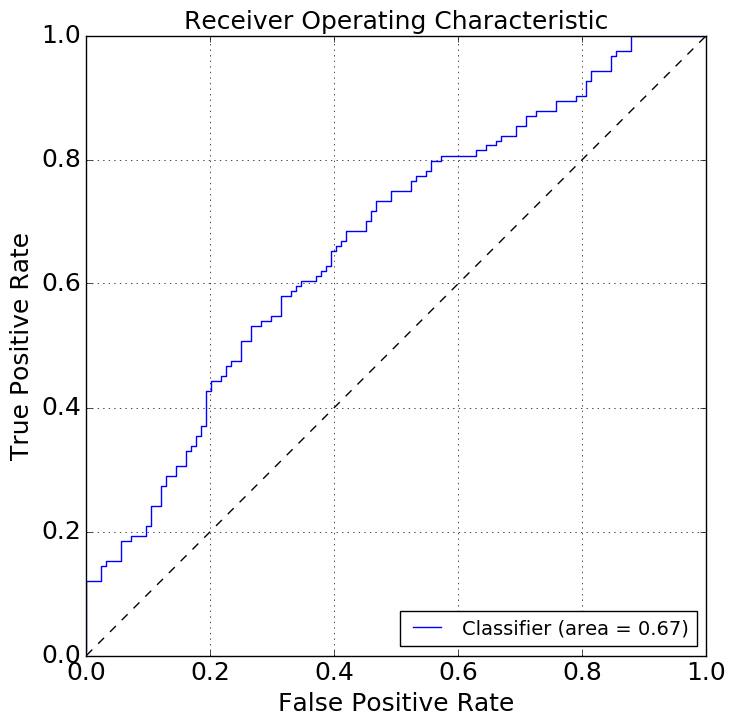
判断预测精度的一种行业标准方法是接收机工作特性(ROC)。您可以用下面的代码使用sklearn和matplotlib从数据中创建它。
ROC是一个真实阳性率和假阳性率的二维图.你希望这条线高于对角线,越高越好。曲线下面积(AUC)是衡量精度的标准标准:分类器越大,分类器就越精确。
import pandas as pd
# read data
df = pd.read_csv('sample_data.csv', header=None, names=['classifier','category'])
# remove values that are not 0 or 1 (two of those)
df = df.loc[(df.category==1.0) | (df.category==0.0),:]
# examine data frame
df.head()
from matplotlib import pyplot as plt
# add this magic if you're in a notebook
# %matplotlib inline
from sklearn.metrics import roc_curve, auc
# matplot figure
figure, ax1 = plt.subplots(figsize=(8,8))
# create ROC itself
fpr,tpr,_ = roc_curve(df.category,df.classifier)
# compute AUC
roc_auc = auc(fpr,tpr)
# plotting bells and whistles
ax1.plot(fpr,tpr, label='%s (area = %0.2f)' % ('Classifier',roc_auc))
ax1.plot([0, 1], [0, 1], 'k--')
ax1.set_xlim([0.0, 1.0])
ax1.set_ylim([0.0, 1.0])
ax1.set_xlabel('False Positive Rate', fontsize=18)
ax1.set_ylabel('True Positive Rate', fontsize=18)
ax1.set_title("Receiver Operating Characteristic", fontsize=18)
plt.tick_params(axis='both', labelsize=18)
ax1.legend(loc="lower right", fontsize=14)
plt.grid(True)
figure.show()从你的数据,你应该得到一个像这样的情节:
https://stackoverflow.com/questions/42871043
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号