
Tensorflow / Deepmind:对于与证明相关的数学算法,我如何从观察中采取行动?
这个问题是询问有关使用deepmind库的指导/建议/帮助:https://github.com/deepmind/lab或https://www.tensorflow.org/在Python中。
考虑到我是新的概念,如深入学习和人工智能。
问题如下:
- 在数学问题中使用Deepmind或Tensorflow,我需要观察值并采取行动吗?
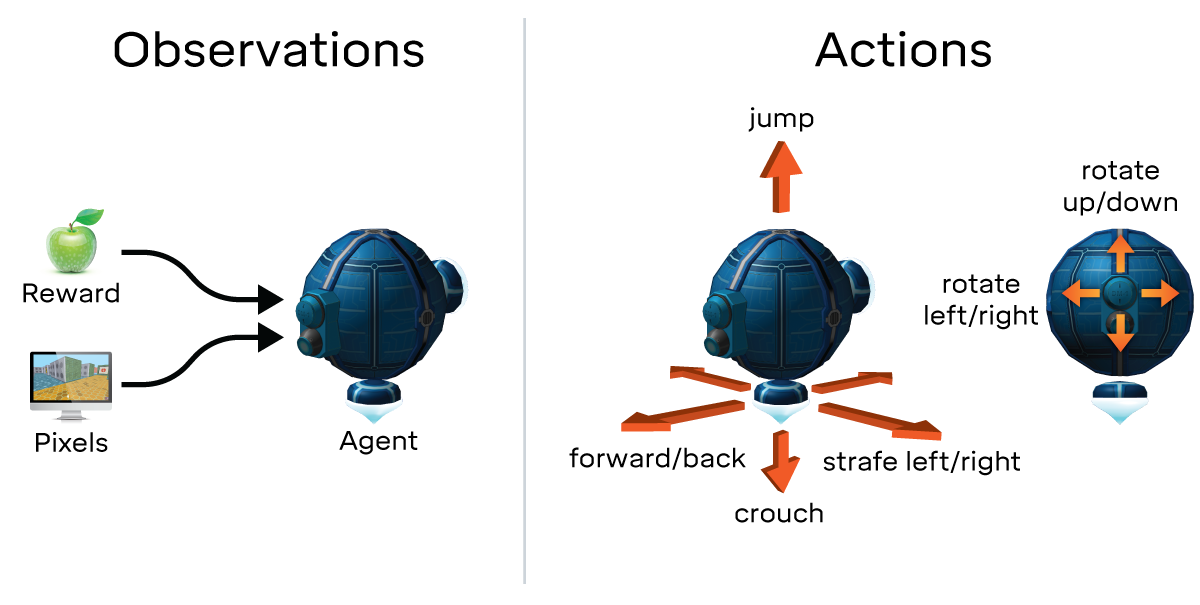
使用一种类似于本页描述的方法(https://deepmind.com/blog/open-sourcing-deepmind-lab/),基于观察、行动、奖励等,我想调用一个学习代理来选择一些价值。我在想这样的事情:
- 输入:元组列表(列表将在每一步更改)
- 行动:从输入中获取一个值(根据经验)
- 奖励:如果它返回的值对我正在实现的算法的其余部分是好的还是坏的,我将奖励深度学习代理。
补充说明:
- 我不能事先训练藻类。
输入的内容如下(只有数字):
edge: (1, 2), face_down: 4, face_up: 5, face_left: 4, face_right: 5
edge: (0, 1), face_down: 4, face_up: 4, face_left: 4, face_right: 5
edge: (5, 4), face_down: 4, face_up: 5, face_left: 4, face_right: 5
edge: (6, 7), face_down: 3, face_up: 5, face_left: 5, face_right: 5
edge: (3, 0), face_down: 4, face_up: 4, face_left: 5, face_right: 4
edge: (4, 1), face_down: 4, face_up: 5, face_left: 5, face_right: 4
edge: (8, 5), face_down: 4, face_up: 5, face_left: 5, face_right: 4
edge: (3, 8), face_down: 4, face_up: 5, face_left: 4, face_right: 5
edge: (2, 3), face_down: 4, face_up: 5, face_left: 5, face_right: 4
edge: (5, 0), face_down: 4, face_up: 4, face_left: 5, face_right: 4
edge: (0, 5), face_down: 4, face_up: 4, face_left: 4, face_right: 5
edge: (1, 0), face_down: 4, face_up: 4, face_left: 5, face_right: 4
edge: (9, 6), face_down: 3, face_up: 5, face_left: 5, face_right: 5
edge: (0, 3), face_down: 4, face_up: 4, face_left: 4, face_right: 5
edge: (7, 9), face_down: 3, face_up: 5, face_left: 5, face_right: 5这样做的目的是使用同样的deepmind来玩游戏,而不是分析像素和使用pad (上、下、左、右、火、跳),而是让学习代理分析一些数学值,作为唯一的行动,选择其中一个。
是否有其他方法或库/框架来解决这一问题?
回答 1
Stack Overflow用户
发布于 2018-08-21 15:49:29
在你的例子中,你似乎在做一个与背景有关的强盗问题。用Bellman方程来解决你的问题应该非常简单。
算法将如下所示:
1)把你的数学值(州)灌输给你的强盗。
2)让你的强盗选择它认为是最好的行动(在开始时,这将是随机的)。
3)在给予这些国家的情况下,因执行该行动而获得奖励。
在这里可以找到编码和实现的一个快速示例:
您只需更改奖励设置和状态设置即可。
https://stackoverflow.com/questions/42809054
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号