
Python发布USPTO站点抓取请求
Python发布USPTO站点抓取请求
提问于 2017-03-05 21:00:33
我正试着从http://portal.uspto.gov/EmployeeSearch/网站上搜集数据。在浏览器中打开站点,单击网站的“组织搜索”中的“搜索”按钮,然后查找发送给服务器的请求。
当我在我的程序中使用python请求库发布相同的请求时,我没有得到我期望的结果页面,但是我得到了相同的搜索页面,其中没有员工数据。我试过所有的变体,似乎都没有用。
我的问题是,我应该在请求中使用什么URL,是否需要指定标头(也尝试过,在Firefox developer工具中查看复制的头)或其他什么?
下面是发送请求的代码:
import requests
from bs4 import BeautifulSoup
def scrape_employees():
URL = 'http://portal.uspto.gov/EmployeeSearch/searchEm.do;jsessionid=98BC24BA630AA0AEB87F8109E2F95638.prod_portaljboss4_jvm1?action=displayResultPageByOrgShortNm¤tPage=1'
response = requests.post(URL)
site_data = response.content
soup = BeautifulSoup(site_data, "html.parser")
print(soup.prettify())
if __name__ == '__main__':
scrape_employees()回答 1
Stack Overflow用户
回答已采纳
发布于 2017-03-07 01:42:49
您需要的所有数据都在一个form标记中:
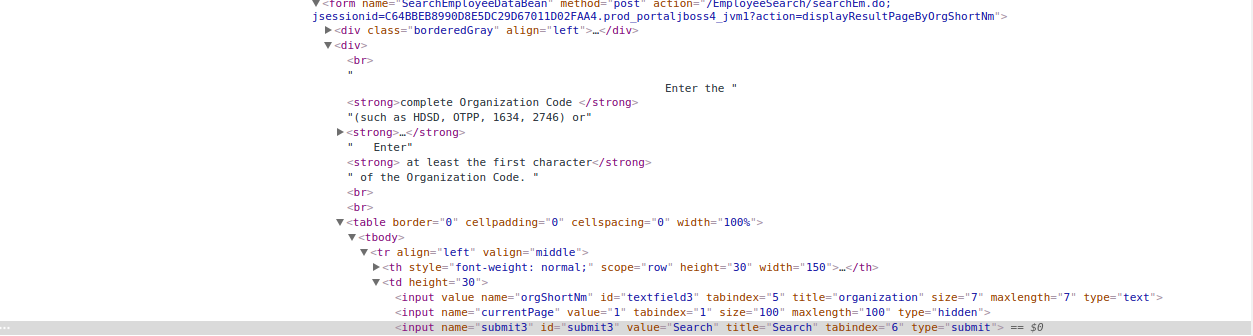
action是发送到服务器时的url。
input是您需要将数据发送到服务器的数据。{name:value}
import requests, bs4, urllib.parse,re
def make_soup(url):
r = requests.get(url)
soup = bs4.BeautifulSoup(r.text, 'lxml')
return soup
def get_form(soup):
form = soup.find(name='form', action=re.compile(r'OrgShortNm'))
return form
def get_action(form, base_url):
action = form['action']
# action is reletive url, convert it to absolute url
abs_action = urllib.parse.urljoin(base_url, action)
return abs_action
def get_form_data(form, org_code):
data = {}
for inp in form('input'):
# if the value is None, we put the org_code to this field
data[inp['name']] = inp['value'] or org_code
return data
if __name__ == '__main__':
url = 'http://portal.uspto.gov/EmployeeSearch/'
soup = make_soup(url)
form = get_form(soup)
action = get_action(form, url)
data = get_form_data(form, '1634')
# make request to the action using data
r = requests.post(action, data=data)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/42613938
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号