
在Neo4j中,可以找到所有节点的关系是另一个节点关系的超集的节点吗?
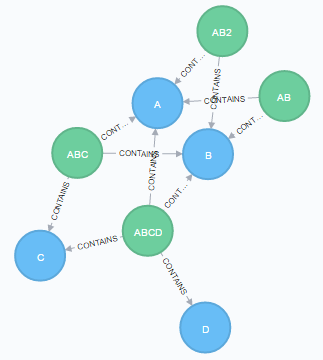
考虑到以下人为的数据库:
CREATE (a:Content {id:'A'}),
(b:Content {id:'B'}),
(c:Content {id:'C'}),
(d:Content {id:'D'}),
(ab:Container {id:'AB'}),
(ab2:Container {id:'AB2'}),
(abc:Container {id:'ABC'}),
(abcd:Container {id:'ABCD'}),
((ab)-[:CONTAINS]->(a)),
((ab)-[:CONTAINS]->(b)),
((ab2)-[:CONTAINS]->(a)),
((ab2)-[:CONTAINS]->(b)),
((abc)-[:CONTAINS]->(a)),
((abc)-[:CONTAINS]->(b)),
((abc)-[:CONTAINS]->(c)),
((abcd)-[:CONTAINS]->(a)),
((abcd)-[:CONTAINS]->(b)),
((abcd)-[:CONTAINS]->(c)),
((abcd)-[:CONTAINS]->(d))是否有一个查询可以检测所有Container节点对,其中一个CONTAINS或者是与另一个Container节点相同的Content节点的超集?
对于我的示例数据库,我希望查询返回:
(ABCD) is a superset of (ABC), (AB), and (AB2)
(ABC) is a superset of (AB), and (AB2)
(AB) and (AB2) contain the same nodes如果密码不适合这样做,但是另一种查询语言非常适合它,或者如果Neo4j不适合这样做,但是另一个数据库非常适合它,我也希望能够对此进行输入。
应答查询性能(截至2017-02-28T21:56Z)
对于Neo4j或图形数据库查询,我还没有足够的经验来分析答案的性能,我还没有为更有意义的比较构建我的大数据集,但我认为我应该使用PROFILE命令运行每个数据集,并列出DB命中成本。我省略了计时数据,因为我无法使它与如此小的数据集保持一致或有意义。
- stdob- 129次总命中次数
- :46次总点击次数
- InverseFalcon: 27分贝点击率
回答 3
Stack Overflow用户
发布于 2017-02-27 20:33:29
// Get contents for each container
MATCH (SS:Container)-[:CONTAINS]->(CT:Content)
WITH SS,
collect(distinct CT) as CTS
// Get all container not equal SS
MATCH (T:Container)
WHERE T <> SS
// For each container get their content
MATCH (T)-[:CONTAINS]->(CT:Content)
// Test if nestd
WITH SS,
CTS,
T,
ALL(ct in collect(distinct CT) WHERE ct in CTS) as test
WHERE test = true
RETURN SS, collect(T)Stack Overflow用户
发布于 2017-02-27 20:14:59
这是第一次尝试。我相信这可以用一些精益求精,但这应该会让你走。
// find the containers and their contents
match (n:Container)-[:CONTAINS]->(c:Content)
// group the contents per container
with n as container, collect(c.id) as contents
// combine the continers and their contents
with collect(container{.id, contents: contents}) as containers
// loop through the list of containers
with containers, size(containers) as container_size
unwind range(0, container_size -1) as i
unwind range(0, container_size -1) as j
// for each container pair compare the contents
with containers, i, j
where i <> j
and all(content IN containers[j].contents WHERE content in containers[i].contents)
with containers[i].id as superset, containers[j].id as subset
return superset, collect(subset) as subsetsStack Overflow用户
发布于 2017-02-28 13:09:56
在获取容器及其收集的内容之后,我将使用的方法是通过计算容器的内容来筛选哪些容器彼此比较,然后运行来自APOC过程的apoc.coll.containsAll()对超集/等价物集进行筛选。最后,您可以比较内容的数量,以确定它是超集还是等号集,然后再收集。
就像这样:
match (con:Container)-[:CONTAINS]->(content)
with con, collect(content) as contents
with collect({con:con, contents:contents, size:size(contents)}) as all
unwind all as first
unwind all as second
with first, second
where first <> second and first.size >= second.size
with first, second
where apoc.coll.containsAll(first.contents, second.contents)
with first,
case when first.size = second.size and id(first.con) < id(second.con) then second end as same,
case when first.size > second.size then second end as superset
with first.con as container, collect(same.con) as sameAs, collect(superset.con) as supersetOf
where size(sameAs) > 0 or size(supersetOf) > 0
return container, sameAs, supersetOf
order by size(supersetOf) desc, size(sameAs) deschttps://stackoverflow.com/questions/42494020
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号