
在使用HIP C++的AMD上使用“What”操作的要求是什么?
有AMD HIP C++,非常类似于CUDA C++。此外,AMD还创建了Hipify,将CUDA C++转换为HIP C++ (便携式C++代码),该代码可以在nVidia GPU和AMD:https://github.com/GPUOpen-ProfessionalCompute-Tools/HIP上执行。
- 在
shflGPU:shfl#requirement-for-nvidia上使用nVidia操作是有要求的
对nvidia的要求 使用此应用程序时,请确保您有一个3.0或更高版本的设备,以便使用warp操作,并在Makefile中添加-gencode arch=compute=30、code=sm_30 nvcc标志。
- 还注意到HIP支持
shfl的64波形(翘曲尺寸)在AMD:faq.md#why-use-hip-rather-than-supporting-cuda-directly上。
此外,HIP还定义了可移植的查询体系结构特性的机制,并支持更大的64位波形大小的,它将交叉车道函数的返回类型从32位ints扩展到64位ints。
但是,哪个AMD支持shfl功能,或者哪个AMD支持shfl,因为它是在AMD上使用本地内存实现的,没有硬件指令寄存器到寄存器?
nVidia GPU需要3.0或更高的计算能力(CUDA CC),但是使用HIP C++在AMD上使用shfl操作有什么要求?
回答 1
Stack Overflow用户
发布于 2017-03-02 17:58:49
- 是,在GPU GCN3 (如
ds_bpermute和ds_permute)中有新的指令,可以提供__shfl()等功能。 - 这些
ds_bpermute和ds_permute指令只使用本地内存路由(LDS8.6TB/s),但实际上不使用本地内存,这允许加快线程之间的数据交换:8.6TB/s<<51.6TB/s:http://gpuopen.com/amd-gcn-assembly-cross-lane-operations/
他们使用LDS硬件在波前的64车道之间路由数据,但实际上并不写入LDS位置。
- 此外,还有一些数据--并行基元(DPP) --当您可以使用它时,它特别强大,因为op可以直接读取相邻工作项的寄存器。也就是说,DPP可以全速访问相邻线程(工作项)~51.6tb/s。
http://gpuopen.com/amd-gcn-assembly-cross-lane-operations/
现在,大多数矢量指令都可以在完全吞吐量的情况下进行跨车道读取.
例如,wave_shr-instruction (波前右移)用于扫描算法
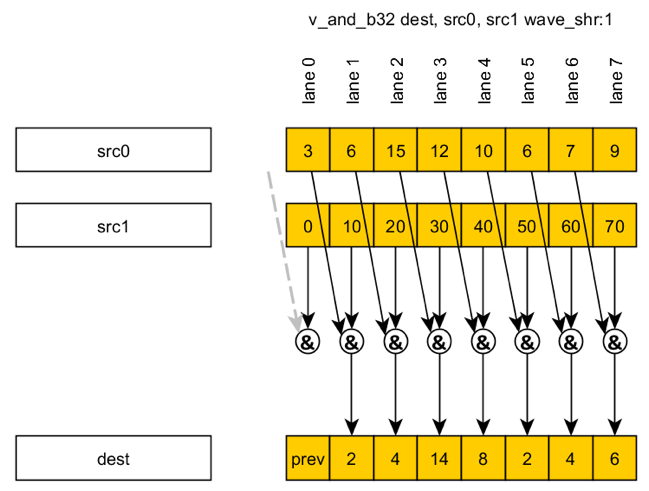
更多关于GCN3:Architecture.pdf的信息
新指令
- “SDWA”-子Dword寻址允许访问VGPR的字节和字的值指令。
- “DPP”--数据并行处理允许价值指令从相邻车道访问数据。
- DS_PERMUTE_RTN_B32,DS_BPERMPUTE_RTN_B32.
..。
DS_PERMUTE_B32向前变换。不编写任何LDS内存。
https://stackoverflow.com/questions/42468984
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号