
基于唯一列交互的虚拟变量
基于唯一列交互的虚拟变量
提问于 2017-02-16 16:20:19
我有以下数据,并希望为两列之间的每个唯一交互创建一个$ID变量
DATE <- c('V', 'V', 'W', 'W', 'X', 'X', 'Y', 'Y', 'Z', 'Z')
SEX <- rep(1:2, 5)
Blood_T1 <- c(3,4,3,3,4,3,1,6,3,4)
Blood_T2 <- c(4,3,3,3,3,4,6,1,4,3)
df1 <- data.frame(DATE, SEX, Blood_T1, Blood_T2)当按$DATE分组时,我希望为$Blood_T1和$Blood_T2的每个唯一组合创建一个新的虚拟变量,而不管它们的顺序如何。
所需的输出如下:
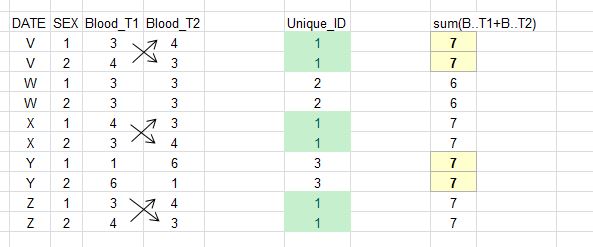
我不能使用和,因为它并不总是产生独特的组合。(请参阅上文以黄色标明的部分以作澄清)
我试过以下命令,但尚未命中要害
with(df1, interaction(Blood_T1, Blood_T2))
as.numeric(as.factor(with(df1, paste(Blood_T1, Blood_T2))))
transform(df1, Cluster_ID = as.numeric(interaction(Blood_T1, Blood_T2, drop=TRUE)))回答 2
Stack Overflow用户
回答已采纳
发布于 2017-02-16 16:28:06
我们可以试试data.table。将“data.frame”转换为“data.table”(setDT(df1)),获取“Blood_T1”和“Blood_T2”列的pmin和pmax,paste,它在一起,将值与unique元素组合起来,以创建“Unique_ID”,然后按“DATE”进行分组,并连接“Blood_T1”和“Blood_T2”的sum以创建“Sum”列。
library(data.table)
setDT(df1)[, Unique_ID := {
i1 <- paste(pmin(Blood_T1, Blood_T2), pmax(Blood_T1, Blood_T2))
match(i1, unique(i1))}]
df1[, Sum := c(sum(Blood_T1), sum(Blood_T2)), DATE][]
# DATE SEX Blood_T1 Blood_T2 Unique_ID Sum
#1: V 1 3 4 1 7
#2: V 2 4 3 1 7
#3: W 1 3 3 2 6
#4: W 2 3 3 2 6
#5: X 1 4 3 1 7
#6: X 2 3 4 1 7
#7: Y 1 1 6 3 7
#8: Y 2 6 1 3 7
#9: Z 1 3 4 1 7
#10: Z 2 4 3 1 7上述方法也可以在base R中实现,即矢量化方法。
i1 <- with(df1, paste(pmin(Blood_T1, Blood_T2), pmax(Blood_T1, Blood_T2)))
df1$Unique_ID <- match(i1, unique(i1))Stack Overflow用户
发布于 2017-02-16 16:37:01
实际上,您可以对单个对($Blood_T1和$Blood_T2)进行排序,并将它们放在一起paste,这已经是一种ID
apply(df1, 1, function(x) paste(sort(x[3:4]), collapse = ""))
#[1] "34" "34" "33" "33" "34" "34" "16" "16" "34" "34"如果您想进一步减少它,您可以将其作为一个因素来处理,并获得数值。
as.numeric(as.factor(apply(df1, 1, function(x) paste(sort(x[3:4]), collapse = ""))))
#[1] 3 3 2 2 3 3 1 1 3 3如果有必要的话,你也可以加入DATE
apply(df1, 1, function(x) paste(sort(x[c(1,3:4)]), collapse = ""))
#[1] "34V" "34V" "33W" "33W" "34X" "34X" "16Y" "16Y" "34Z" "34Z"页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/42279343
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号