
我是否应该规范我的神经网络中的输入?
首先是一些背景。
我正在做一个非常复杂的项目,制作一个神经网络,可以在一个很好的水平上玩国际象棋。我可能不会成功,但我这么做主要是为了学习如何学习这种机器学习。
我决定用遗传算法训练网络,在不同的神经网络在几局棋中互相对抗之后,调整权重。
每个神经元在经过处理后使用双曲正切(-1,1)对数据进行规范化,但在进入网络之前还没有对输入进行归一化。
我从长颈鹿国际象棋引擎中获得了一些灵感,尤其是输入。
它们看起来就像这样:
第一层:
- 剩余白卒数(0-8)
- 剩余黑卒数(0-8)
- 剩余白衣骑士数(0-2)
- 剩余黑骑士数(0-2)
……
第二层仍与第一层相同:
- 典当1的位置(可能有2个值,x0-7和y0-7)
- 典当2的位置
..。
- 女皇1的位置
- 皇后2的位置
..。
第三层,同样位于前两层的同一层。数据只有在下一层抽象之后才会出现“串扰”。
- 被Pawn1攻击的碎片的值(这将在0-12 ish范围内)
- 受Pawn2攻击的件的值
..。
- 被Bishop1攻击的碎片的价值
你明白了吧。
如果你不这么做的话,我的意思是画得很糟糕:
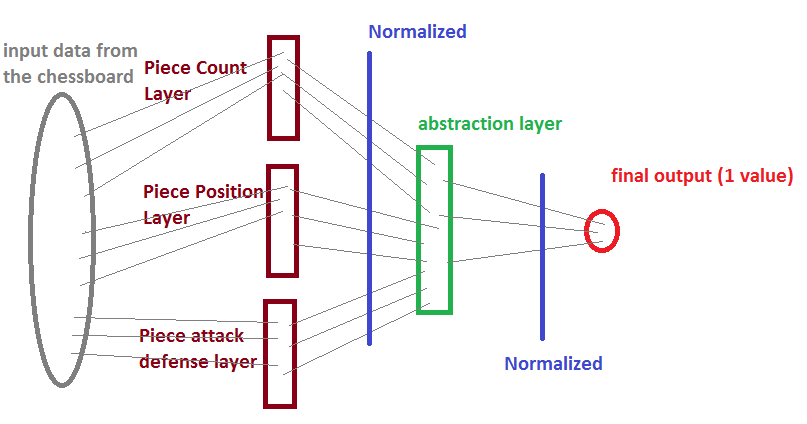
问题是:在神经网络读取输入数据之前,我是否应该对其进行规范化?
我觉得压缩数据可能不是一个好主意,但我真的没有能力做出一个决定性的决定。
我希望在座的人能在这个问题上启发我,如果你认为我应该使数据正常化,我希望你能提出一些这样做的方法。
谢谢!
回答 1
Stack Overflow用户
发布于 2017-02-17 00:02:56
您不应该需要规范网络内部的任何。机器学习的目的是训练权重和偏差来学习非线性函数,在你的例子中,这是静态的国际象棋评估。因此,您的第二个规范化的蓝色垂直条(接近最终输出)是不必要的。
注意: Hidden layers是一个比abstraction layer更好的术语,所以我将使用它。
隐藏层之前的另一个规范化是可选的,但建议您这样做。这还取决于我们正在讨论的输入。
长颈鹿论文在第18页写道:
“每个插槽都有正规化x坐标,归一化y坐标.”
国际象棋有64个正方形,如果不进行归一化,范围将是0,1,....63。这是非常离散的,范围远高于其他输入(稍后更多)。将它们规范化为更易于管理和可与其他输入相比较的东西是有意义的。论文没有提到,它是如何被规范化的,但是我不明白为什么0.1范围不能工作。对进行正规化国际象棋方块(或坐标)是有意义的。
其他输入,如董事会上是否有女王,是正确的还是错误的,因此不需要标准化。例如,长颈鹿论文在第18页写道:
..。无论作品是否存在.
很明显,你不会让它正常化。
回答你的问题
- 如果您像在长颈鹿中一样表示片计数层,则不需要标准化。但是,如果您希望使用0..8中的离散表示,则可能希望将其规范化。
- 如果你用棋盘表示块位置层,你应该像长颈鹿一样正常化。
- 长颈鹿不规范
Piece Attack Defense Layer,可能它将信息表示为the lowest-valued attacker and defender of each square。不幸的是,论文没有明确说明这是如何做到的。您的实现可能需要规范化,所以请使用您的常识。
如果没有任何先前的假设,哪些特性将与模型更相关,您应该将它们规范化为可比较的缩放。
编辑的
让我回答你的意见。规范化不是正确的术语,您所说的是激活函数(function)。归一化和激活函数不是一回事。
https://stackoverflow.com/questions/42264684
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号