
Hadoop看不到我的输入目录。
我遵循的是Apache还原教程,我正在分配输入和输出目录。我在这里创建了两个目录:
~/projects/hadoop/WordCount/input/
~/projects/hadoop/WordCount/output/但是当我运行fs时,文件和目录就找不到了。我以ubuntu用户的身份运行,它拥有目录和输入文件。
基于下面建议的解决方案,我尝试了::
找到我的hdfs目录hdfs dfs -ls /,它是/tmp,我用mkdir创建了输入/输出/在/tmp中
试图复制本地.jar to.hdfs:
hadoop fs -copyFromLocal ~projects/hadoop/WordCount/wc.jar /tmp接收:
copyFromLocal: `~projects/hadoop/WordCount/wc.jar': No such file or directory
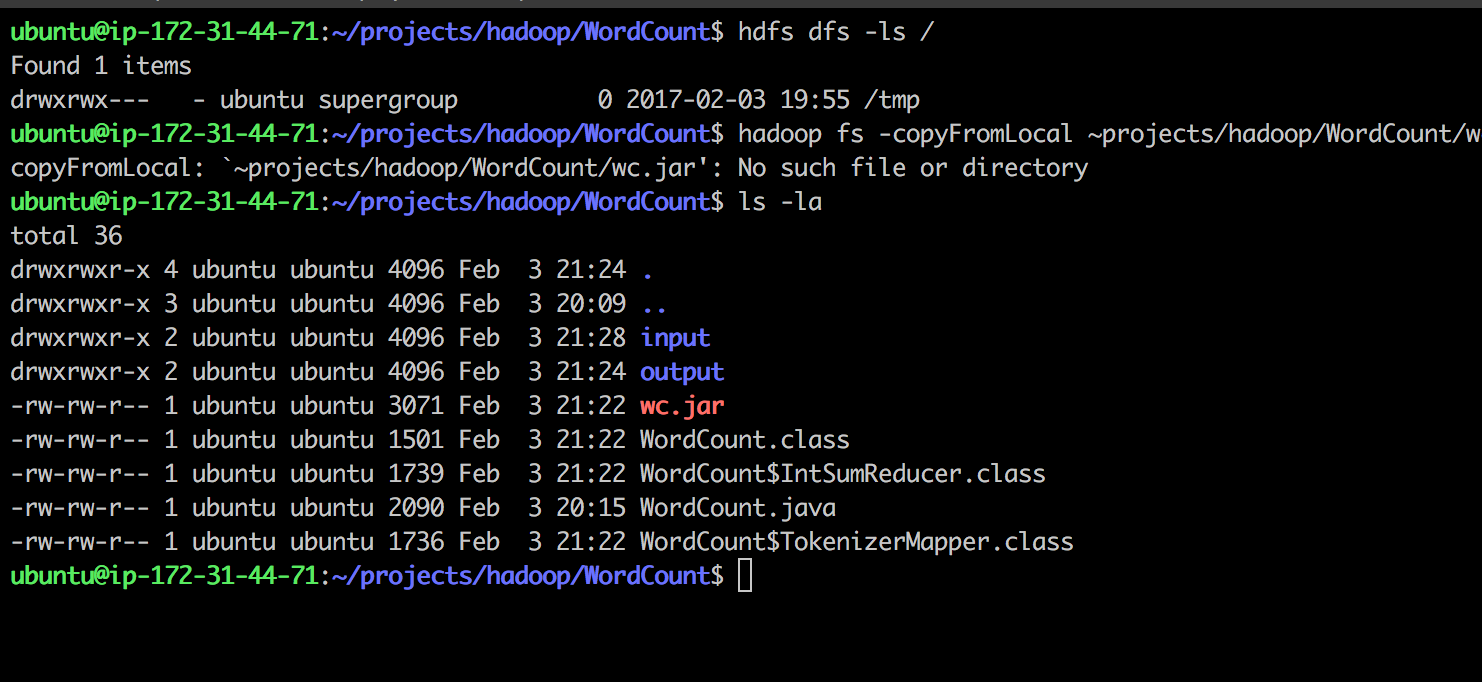
有什么疑难解答吗?谢谢
回答 2
Stack Overflow用户
发布于 2017-02-04 14:50:54
MapReduce期望Input和Output路径是HDFS中的目录,而不是本地的,除非集群是在本地模式下配置的。此外,输入目录必须存在,而输出不应该存在。
例如,:
如果输入是/mapreduce/wordcount/input/,则必须创建包含其中所有输入文件的目录。使用HDFS命令创建它们。
hdfs dfs -mkdir -p /mapreduce/wordcount/input/
hdfs dfs -copyFromLocal file1 file2 file3 /mapreduce/wordcount/input/file1 file2 file3是本地可用的输入文件
如果输出是/examples/wordcount/output/。父目录必须存在,但不存在output/目录。Hadoop在作业执行时创建它。
hdfs dfs -mkdir -p /examples/wordcount/用于作业的jar (在本例中是wc.jar )应该驻留在本地,并且在执行时提供命令的绝对或相对本地路径。
所以最后的命令看起来就像
hadoop jar /path/where/the/jar/is/wc.jar ClassName /mapreduce/wordcount/input/ /examples/wordcount/output/Stack Overflow用户
发布于 2017-02-04 04:03:29
正如hadoop无效的输入异常提示的那样,它找不到位置"/home/ubuntu/projects/hadoop/WordCount/input".。
是本地路径还是HDFS路径?我认为这是本地的,这就是为什么会发生输入异常。
要执行jar文件,必须将jar放在HDFS目录中。并且输入和输出目录也必须在HDFS中。
使用copyFromLocal命令将jar从本地目录复制到hadoop目录,如下所示:
hadoop fs -copyFromLocal <localsrc>/wc.jar hadoop-dirhttps://stackoverflow.com/questions/42033601
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号