
什么是行切片与什么是列切片?
是的,我读过这和这个答案,但我仍然无法理解它.这是个基本问题。
在:
M[:, index]
M[index, :]哪个是slicing 行切片,哪个是列
对于我的问题,如果我想对列执行高级索引,如:
M[:, indexes] # indexes is an array like [0, 4, 9]哪种稀疏矩阵类型最适合做M[:, indexes]**,[CSR](https://docs.scipy.org/doc/scipy-0.18.1/reference/generated/scipy.sparse.csr_matrix.html#scipy.sparse.csr_matrix) 或 [CSC](https://docs.scipy.org/doc/scipy-0.18.1/reference/generated/scipy.sparse.csc_matrix.html#scipy.sparse.csc_matrix) ?**
回答 3
Stack Overflow用户
发布于 2017-02-02 10:26:15
实际上,行/列切片也不是:这些都是行/列索引的示例。
M[index, :]是行索引M[:, index]是列索引M[start:stop, :]是行切片M[:, start:stop]是列切片
CSC在检索整个列时效率更高:特定列的非零值和匹配的行索引内部存储为内存中的连续数组。
对于CSR和整个行的检索,对偶是正确的。
Stack Overflow用户
发布于 2017-02-02 18:12:07
虽然行选择对于csr比对于col选择更快,但差别并不大:
In [288]: Mbig=sparse.rand(1000,1000,.1, 'csr')
In [289]: Mbig[:1000:50,:]
Out[289]:
<20x1000 sparse matrix of type '<class 'numpy.float64'>'
with 2066 stored elements in Compressed Sparse Row format>
In [290]: timeit Mbig[:1000:50,:]
1000 loops, best of 3: 1.53 ms per loop
In [291]: timeit Mbig[:,:1000:50]
100 loops, best of 3: 2.04 ms per loop
In [292]: Mbig=sparse.rand(1000,1000,.1, 'csc')
In [293]: timeit Mbig[:1000:50,:]
100 loops, best of 3: 2.16 ms per loop
In [294]: timeit Mbig[:,:1000:50]
1000 loops, best of 3: 1.65 ms per loop转换格式是不值得的
In [295]: timeit Mbig.tocsr()[:1000:50,:]
...
100 loops, best of 3: 2.46 ms per loop将此与稠密版本的相同切片进行对比:
In [297]: A=Mbig.A
In [298]: timeit A[:,:1000:50]
...
1000000 loops, best of 3: 557 ns per loop
In [301]: timeit A[:,:1000:50].copy()
...
10000 loops, best of 3: 52.5 µs per loop使比较更加复杂的是,使用数组(numpy高级)进行索引实际上比使用“片”更快:
In [308]: idx=np.r_[0:1000:50] # expand slice into array
In [309]: timeit Mbig[idx,:]
1000 loops, best of 3: 1.49 ms per loop
In [310]: timeit Mbig[:,idx]
1000 loops, best of 3: 513 µs per loop在这里,csc的列索引具有更大的速度改进。
单行或单列、csr和csc都有getrow/col方法:
In [314]: timeit Mbig.getrow(500)
1000 loops, best of 3: 434 µs per loop
In [315]: timeit Mbig.getcol(500) # 1 column from csc is fastest
10000 loops, best of 3: 78.7 µs per loop
In [316]: timeit Mbig[500,:]
1000 loops, best of 3: 505 µs per loop
In [317]: timeit Mbig[:,500]
1000 loops, best of 3: 264 µs per loop在https://stackoverflow.com/a/39500986/901925中,我重新创建了sparse用于获取行或列的extractor代码。它构造了一个新的1s和0s的稀疏“向量”,并使用矩阵乘法来“选择”行或列。
Stack Overflow用户
发布于 2017-02-02 09:46:53
偶尔混淆顺序是可以的,我的诀窍是画一个矩阵,记住索引顺序从上到下,然后从左到右依次计数:符号表示法
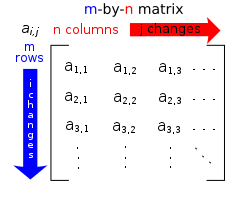
因此,由于:意味着全部,所以您知道[:, i]表示所有行,而[i, :]表示所有列。
对于问题的第二部分:您需要M[:, indices],所以诀窍在于名称:如果您遍历您的列(因为您为所有行指定了列索引),那么您需要压缩稀疏colum格式。在你链接的文档里是这样写的:
CSC格式的优点
- ..。
- 有效列切片
https://stackoverflow.com/questions/41998147
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号