
在特殊情况下使用熊猫(python)将重复数据放到数据帧中
在特殊情况下使用熊猫(python)将重复数据放到数据帧中
提问于 2017-01-30 03:34:18
我有以下数据框架:
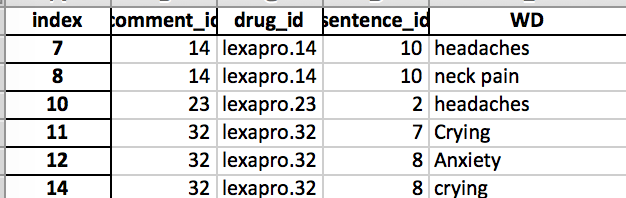
我希望删除WD列中的重复数据,如果它们具有相同的drug_id。
例如,WD列中有两个“哭声”,其drug_id = 32。所以我想移除其中一个哭过的行。
我怎么能做到呢?我知道如何复制行,但不知道如何将此条件添加到此代码中。df = df.apply(lambda x:x.drop_duplicates())
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-01-30 03:38:16
您可以将drop_duplicates与subset参数一起使用,该参数可选择地将某些列视为重复项:
df.drop_duplicates(subset = ["drug_id", "WD"])如果上/下情况对考虑重复很重要,您可以尝试:
df[~df[['drug_id', 'WD']].apply(lambda x: x.str.lower()).duplicated()]在可以将drug_id列和WD列转换为小写的情况下,请使用duplicated()方法标识重复的行,然后使用生成的逻辑序列筛选出重复的行。
示例
df = pd.DataFrame({"A": [1,1,2,2], "B":[1,2,3,4], "C":[1,1,2,3]})
df
# A B C
#0 1 1 1
#1 1 2 1
#2 2 3 2
#3 2 4 3
df.drop_duplicates(subset=['A', 'C'])
# A B C
#0 1 1 1
#2 2 3 2
#3 2 4 3页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/41928667
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号