
火花驱动存储器和执行器存储器
我是Spark的初学者,我正在运行我的应用程序,从文本字段读取14 am的数据,进行一些转换和操作(收集,collectAsMap),并将数据保存到数据库
我在带有16G内存的macbook中本地运行它,其中有8个逻辑核。
Java堆设置为12G。
下面是我用来运行应用程序的命令。
bin/spark提交--类com.myapp.application --主控本地*--执行器-内存2G -驱动程序-内存4G /jars/application.jar
我收到以下警告
2017-01-13 16:57:31.579执行器任务启动工人-8小时警告org.apache.spark.storage.MemoryStore -没有足够的空间来缓存rdd_57_0的内存!(迄今计算的26.4 MB )
有人能指导我这里出了什么问题,以及如何提高我的表现吗?另外,如何优化苏打溢油?这里是在我的本地系统中发生的泄漏事件的一个视图。
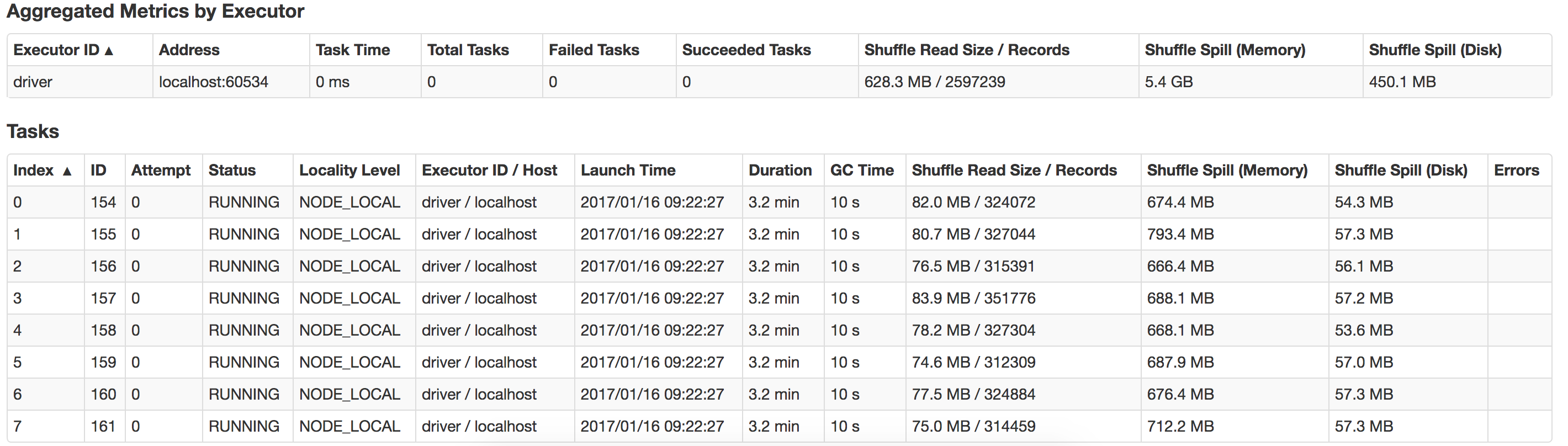
回答 2
Stack Overflow用户
发布于 2017-01-14 03:26:51
运行内存过多的执行器通常会导致过多的垃圾收集延迟。因此,分配更多的内存不是一个好主意。因为您只有14 4GB的数据,2GB的执行器内存和4GB的驱动程序内存就足够了。分配这么多内存是没有用的。您甚至可以使用100 2GB内存运行此作业,性能将比2GB更好。
当您以纱线-群集模式运行应用程序时,驱动程序内存更有用,因为应用程序主程序运行驱动程序。在这里,您正在以本地模式运行您的应用程序,driver-memory是不必要的。您可以从作业中删除此配置。
在您的应用程序中,您已经分配了
Java Max heap is set at: 12G.
executor-memory: 2G
driver-memory: 4G总内存allotment= 16 and,而您的macbook只有16 and内存。在这里,您已经将RAM内存的全部分配给您的spark应用程序。
这真是不太好。操作系统本身消耗了大约1GB内存,并且您可能正在运行其他应用程序,这些应用程序也占用了RAM内存。在这里,你实际上分配了更多的内存。这是应用程序抛出错误Not enough space to cache the RDD的根本原因。
- 将Java分配给12 GB是没有用的。你需要把它减少到4GB或更少。
- 将执行器内存减少到
executor-memory 1G或更少 - 由于您正在本地运行,请从配置中删除
driver-memory。
提交你的工作。一切都会顺利进行。
如果您非常希望了解火花内存管理技术,请参阅这篇有用的文章。
Stack Overflow用户
发布于 2017-01-14 03:25:46
在本地模式下,您不需要指定主模式,使用默认参数是可以的。官方网站称,“星火提交脚本被用于启动集群上的应用程序。它可以通过一个统一的界面使用星火支持的所有集群管理器,这样你就不必专门为每个应用程序配置。”.So你最好使用星星之火--在集群中提交,在本地可以使用火花-shell。
https://stackoverflow.com/questions/41645679
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号