
星火流和星火应用程序可以在同一个纱线集群中运行吗?
大家好,新年快乐!
我正在使用Apache、HDFS和Elastichsearch构建lambda架构。在下面的图片中,我想要做的是:
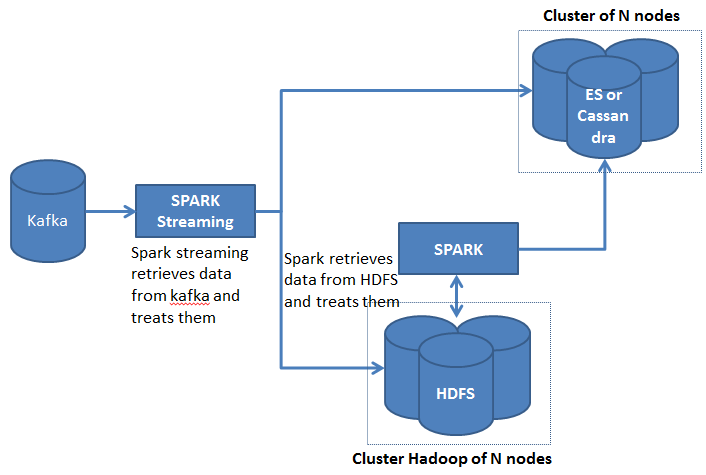
到目前为止,我已经用java为我的星火流和火花应用程序编写了源代码。我在火花文档中读到,火花可以在中间层或纱线杂碎器中运行。如图所示,我已经有了hadoop集群。是否有可能在同一个hadoop集群中运行我的星火流和火花应用程序?如果是,是否有任何特定的配置可执行(例如节点数、RAM.)。还是我必须为火花流添加一个hadoop集群?
我希望我的解释是清楚的。
亚瑟尔
回答 2
Stack Overflow用户
发布于 2017-01-13 15:07:58
您不需要为运行火花流构建单独的集群。
将spark.master属性更改为conf/spark-defaults.conf文件中的yarn-client或yarn-cluster。如有此规定,提交的火花申请将由纱线的ApplicationMaster处理,并由NodeManagers执行。
此外,修改这些核心和内存的属性,使火花与纱对齐。
在spark-defaults.conf中
spark.executors.memory
spark.executors.cores
spark.executors.instances在yarn-site.xml中
yarn.nodemanager.resource.memory-mb
yarn.nodemanager.resource.cpu-vcores否则,它可能导致集群的死锁或资源使用不当。
在纱线上运行星点时,请参考这里进行集群资源管理。
Stack Overflow用户
发布于 2017-01-13 15:04:19
这是可能的。您将流和批处理应用程序提交到同一个纱线集群中。但是,在这两个作业之间共享集群资源可能有点棘手(据我理解)。
因此,我建议您查看火花J观察者来提交您的应用程序。当你想要保持多个火花环境时,星火观察者会让你的生活变得更容易。两个应用程序所需的所有配置都将位于一个位置。
https://stackoverflow.com/questions/41636560
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号