
通过迭代四个连续列来获得数据帧中一行中值的平均值
通过迭代四个连续列来获得数据帧中一行中值的平均值
提问于 2017-01-12 13:01:44
我有一个dataFrame,它包含每个月的GDP值:
[2016-1,2016-2,2016-3,2016-4,2016-5,2016-6,2016-7,2016-8,2016-9,2016-10,2016-11,2016-12]
GDP = pandas.DataFrame(
np.random.randint(1000,1500,size=(10, 12),
columns=[2016-1,2016-2,2016-3,2016-4,2016-5,2016-6,2016-7,2016-8,2016-9,2016-10,2016-11,2016-12])我想对每个季度的月份进行分组,并将3个月的平均值作为每个季度的值。所以
GDP['2000q1'] = (GDP['2016-1'] + GDP['2016-2'] + GDP['2016-3'])/3我是否可以根据列的数目而不是列的名称进行分组?
谢谢
回答 2
Stack Overflow用户
回答已采纳
发布于 2017-01-12 13:20:17
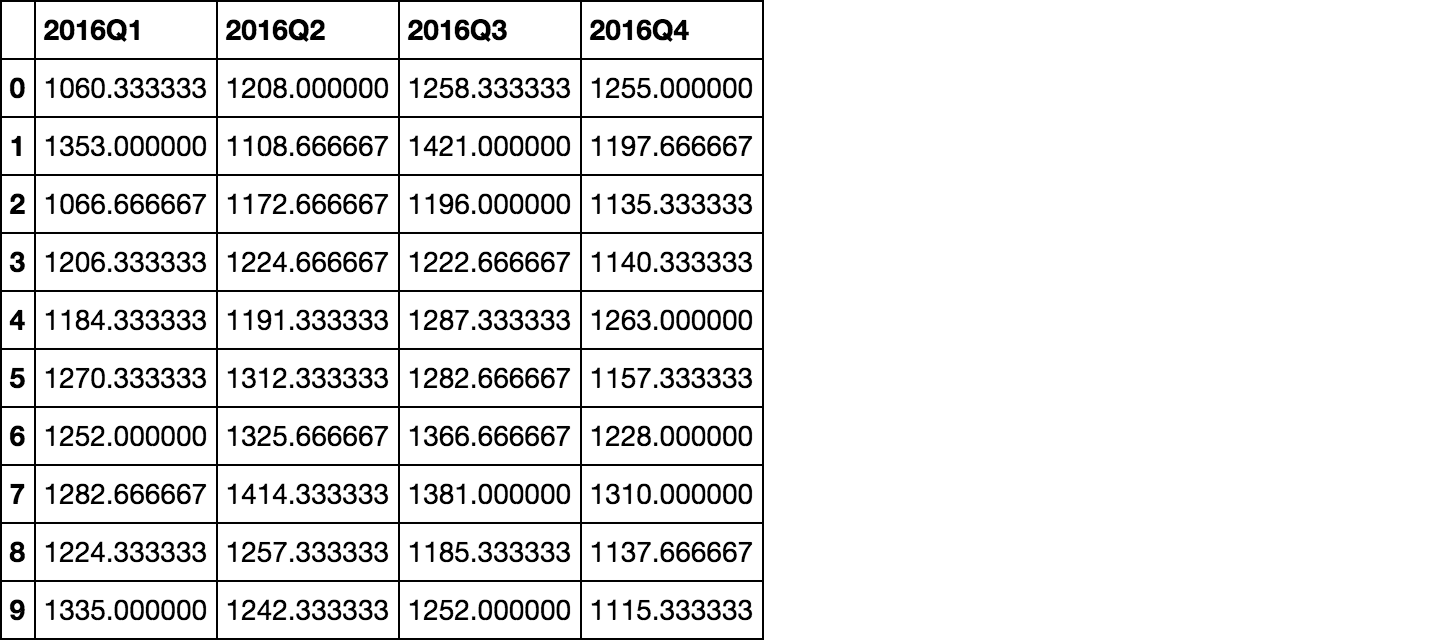
使用resample的
GDP.resample('Q', axis=1).mean()
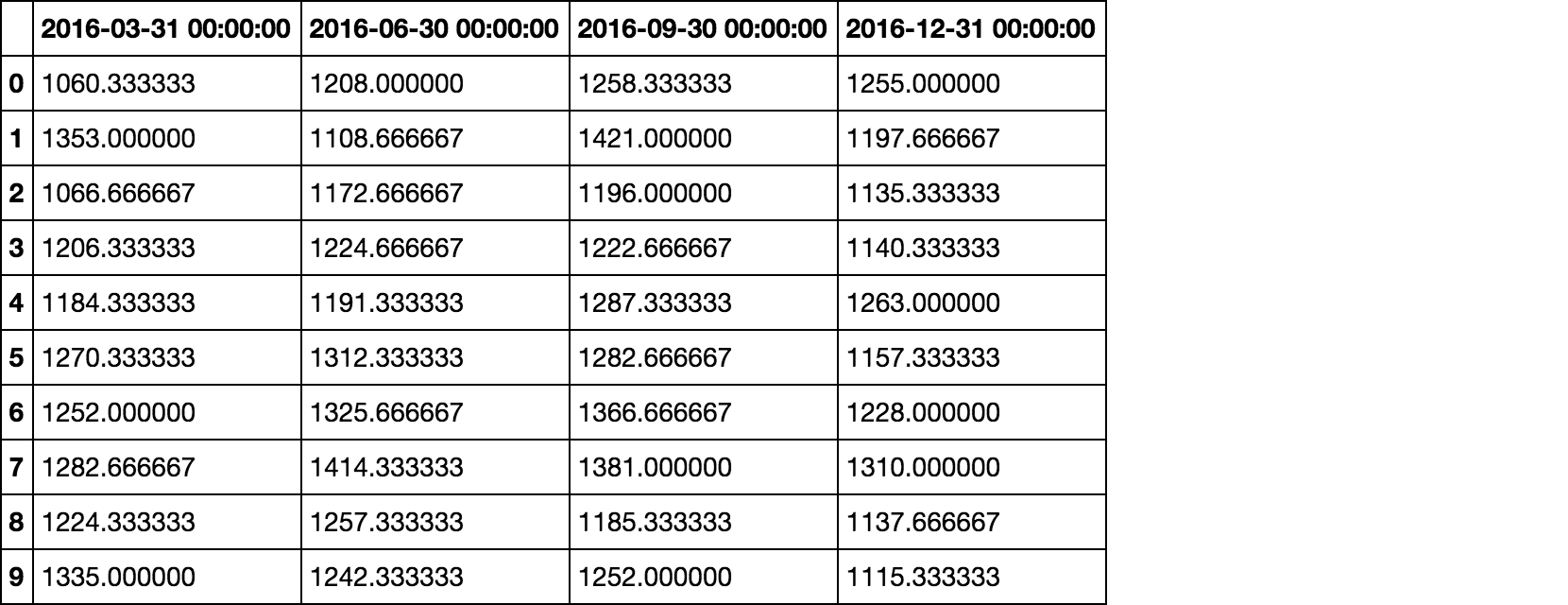
如果我们首先将列转换为句点索引
GDP.columns = GDP.columns.to_period()然后同一条线给我们
GDP.resample('Q', axis=1).mean()
Stack Overflow用户
发布于 2017-01-12 13:24:00
您可以使用.iloc按数字访问列GDP.iloc:,0:3。平均(axis=1)将返回前三列的平均值GDP.iloc:、3:6平均(axis=1)等等。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/41613934
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号