
基于自定义模型的沃森语音文本转换的低精度
沃森会话服务没有识别我的accent.Therefore,我使用了一个自定义模型,下面是使用自定义模型前后的结果。
测试结果
在整合模型之前:-当你有他们的座右铭时。希拉。贾巴在..。那个女人。这个。
在整合模型之后:-我们给了Omatta David。斯里兰卡。贾巴在..。数。州长
实际音频- 音频 49,Wijayaba Mawatha,Kalubowila,Dehiwela,Sri Lanka.Government.Gov。
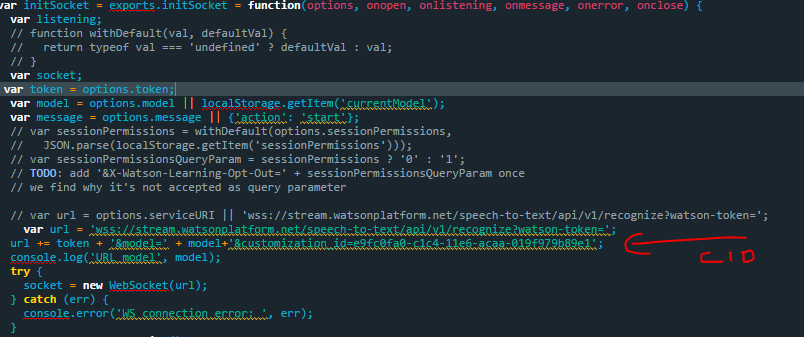
我是如何包含自定义模型的--我在socket.js中使用了演示socket.js中给出的相同文件,我包括了自定义id,如picture.There中所示,还有其他方式包含自定义模型(集成自定义模型的方法),但我想知道我所做的方法是否正确?
下面是我用来创建自定义模型的python代码。代码链接
下面是以JSON格式执行python代码后的语料库结果。语料库文件
这是定制模型(代码中包含的自定义模型文本文件),在那里我已经包括了斯里兰卡的所有道路。
我对文件进行了分叉,并按以下方式编辑了socket.js。
回答 2
Stack Overflow用户
发布于 2017-01-03 22:33:09
首先,除非我遗漏了什么,否则您说的几个单词实际上不会出现在corpus1.txt文件中。显然,服务需要知道你期望它转录的单词。
接下来,该服务面向更常见的语音模式。一个任意名称的列表是很困难的,因为它无法根据上下文猜出一个单词。这通常是自定义语料库提供的内容,但在这种情况下不起作用(除非您碰巧按照它们在语料库中出现的确切顺序读取它们--即使这样,它们也只出现一次,并且没有任何服务已经识别的上下文)。
为了弥补这一点,除了定制单词的语料库外,您可能还需要为其中的许多单词提供一个sounds_like来表示发音:http://www.ibm.com/watson/developercloud/doc/speech-to-text/custom.shtml#addWords。
这是相当多的工作(必须对服务没有正确识别的每个单词进行处理),但是应该可以提高您的结果。
第三,您提供的音频文件有相当数量的背景噪声,这将降低您的结果。一个更好的麦克风/录音位置/等将有所帮助。
最后,用准确的听写和尽可能接近“标准”的美国英语口音更清晰地说话,也有助于提高结果。
Stack Overflow用户
发布于 2017-01-04 16:36:07
我看到的主要问题是音频很吵(我在后台听到火车轨道)。第二个问题是从语料库中提取的OOV单词应该检查其发音的准确性。第三个问题可能是说话人的口音问题(我想你使用的是美国英语模式),而且口音的英语也有问题。至于自定义模型培训数据,您可以尝试重复培训数据中的一些单词(以便对新单词给予更多的权重)。
托尼·李IBM演讲团队
https://stackoverflow.com/questions/41358723
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号