
随机时间段后AWS RDS MySQL性能下降
问题大纲我们的AWS实例在大约7-14天后开始减速,降低了相当大的因子(特定一组查询的加载时间~400%)。RDS监测没有显示出资源短缺的迹象。(有关详细的问题描述,请参见下面的问题更新)
问题更新
因此,经过一个多月的调查和AWS对一些开发人员的支持,我并没有完全接近解决方案。
下面是我从列表中删除的几个步骤,大致没有进一步提示问题:
- 索引/碎片(所有表都有正确的索引/键,没有碎片)
- MySQL统计更新(手动更新统计数据来源)
- 线程并发(将innodb_thread_concurrency更改为各种不同的参数)
- 查询缓存命中率不显示问题
- 解释以查看是否有任何选择实际上是缓慢的或不使用索引/键。
- 慢速查询日志(不返回结果,因为请参阅下面一段,这是一些准备好的选择)
- RDS和EC2在一个VPC内。
作为解释,使用的PlayFramework (2.3.8)有BoneCP,我们使用eBeans来选择数据。因此,基本上,我正在运行一个嵌套对象和所有这些子对象,这将为所讨论的API调用生成几百个准备好的选择。对于使用过的硬件来说,这基本上也是可以的,这些操作既不广泛使用CPU,也不广泛使用RAM。
我还包括了NewRelic来了解这个问题,并做了一些JVM分析。很明显,大部分时间都是由NETTY/eBeans消耗的?
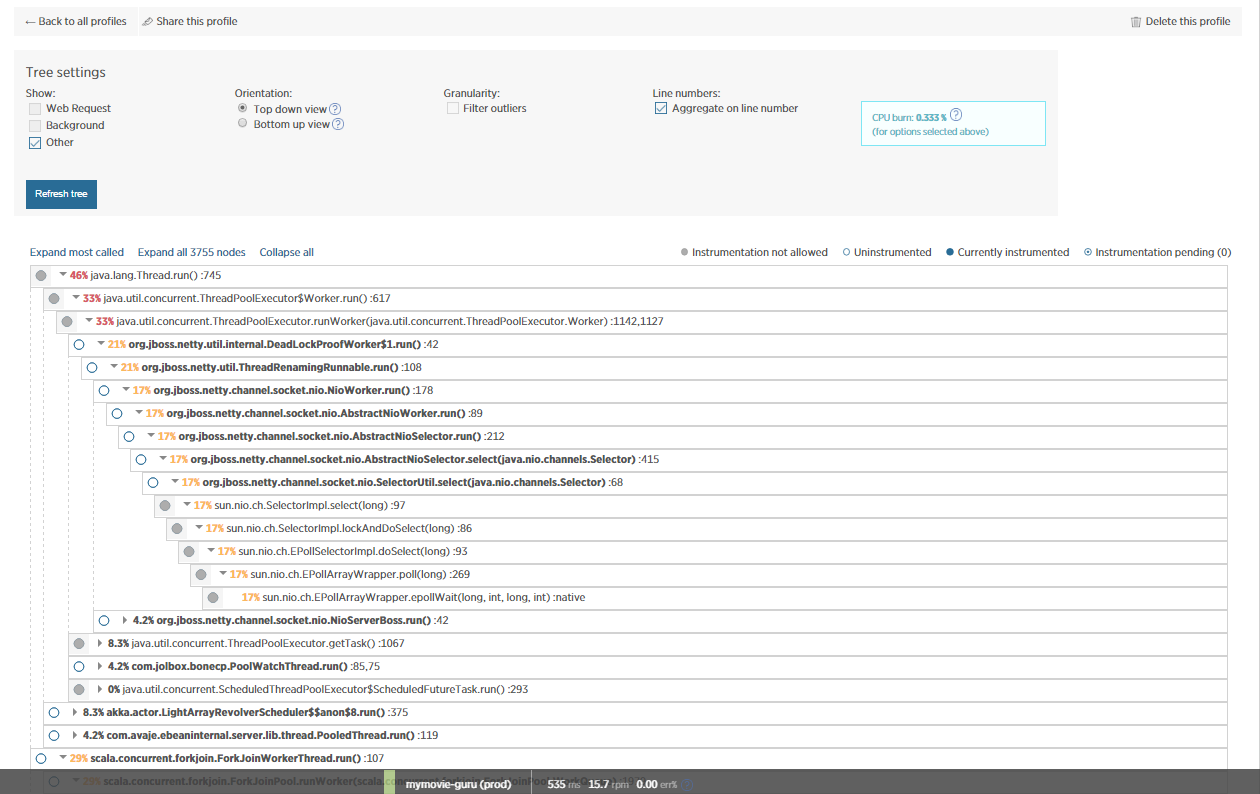
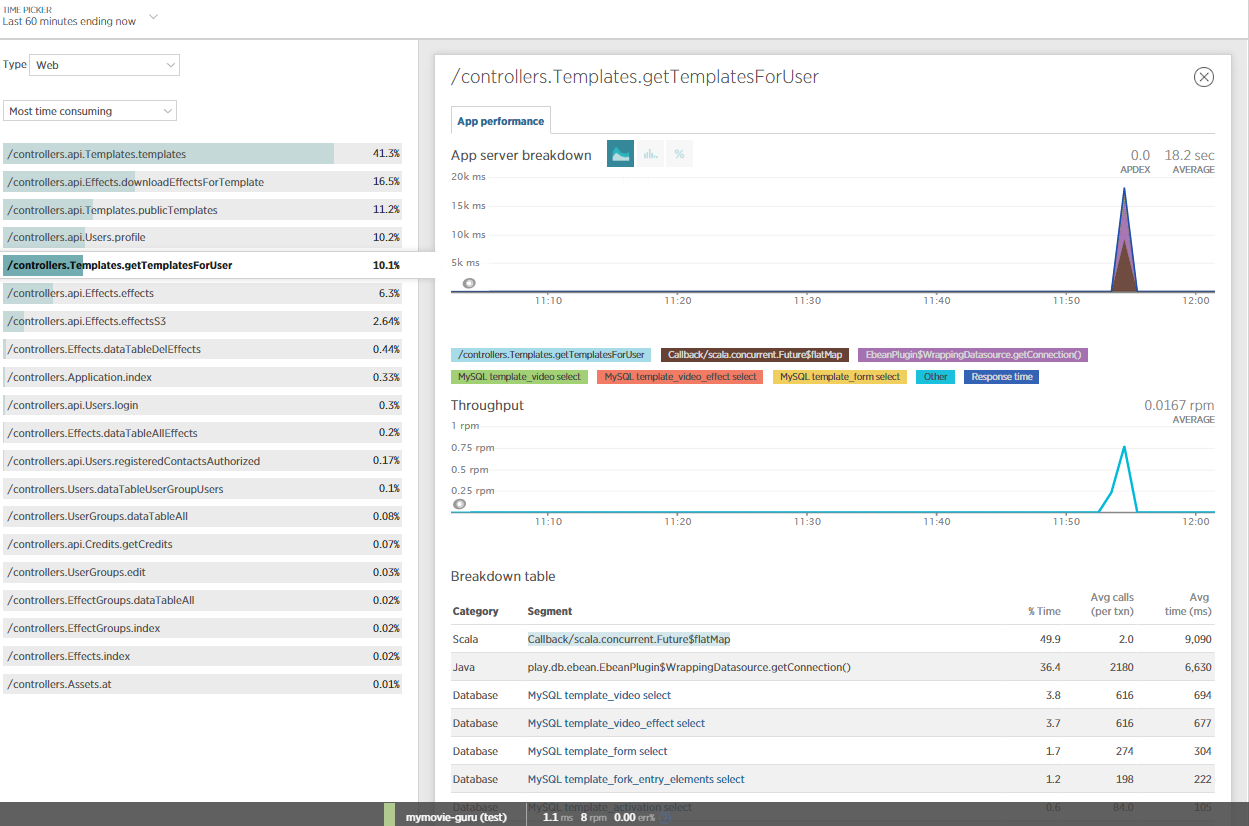
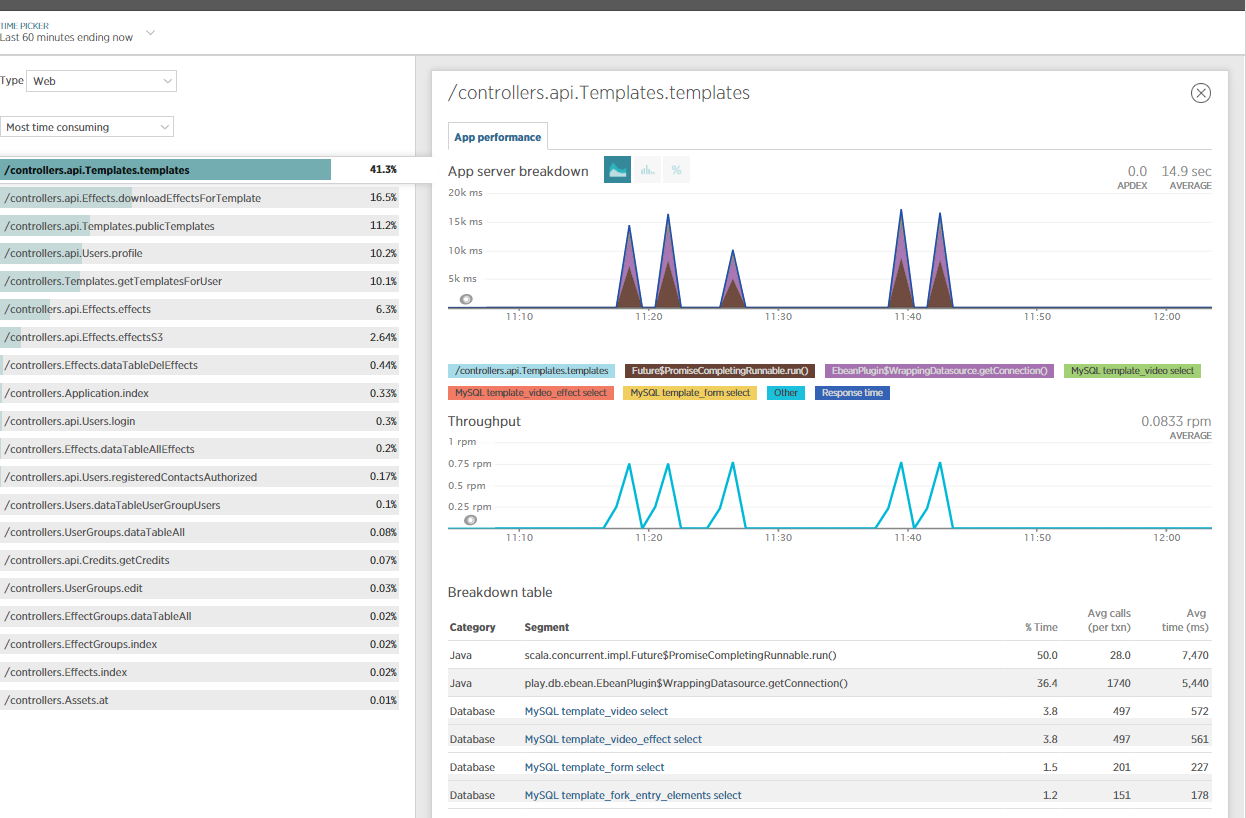
有人能理解这一点吗?
原始问题:问题概要
我们的AWS RDS实例在大约7-14天后开始减速,速度相当大(对于一组特定的查询,大约400%的加载时间)。RDS监测没有显示出资源短缺的迹象。
Infrastructure
我们在AWS EC2实例上运行移动应用程序的PlayFramework后端,连接到AWS实例、一个PROD环境、一个DEV环境。通常,PROD EC2实例指向PROD实例,而DEV EC2指向DEV (来自船长EC2!);然而,有时为了某些测试目的,我们也让EC2指向PROD。正在使用的PlayFramework正在使用BoneCP。
详细问题描述
在一个非常重要的同步过程中,我们的应用程序每天给每个用户多次调用API。我讨论了这个问题功能的背景,感谢评论,我可以确定这个问题是某种MySQL问题。
简而言之,API调用正在加载一组数据,最大值约为1MB的json数据,目前需要大约18s才能加载。当事情运行得很好时,这需要大约4s的时间来加载。
奇怪的是,上一次“解决”的问题是将RDS实例升级到另一个实例类型(从db.m3.large升级到db.m4.large,这只是一个非常微不足道的步骤)。现在,在大约2-3周之后,RDS实例再次表现得像以前一样缓慢。重新启动RDS实例没有显示任何效果。此外,重新启动EC2实例也没有显示任何效果。
我还检查了是否正确设置了受影响的mySQL表的索引,情况就是这样。API调用本身并不急于加载任何BLOB字段或类似的字段,我对此进行了反复检查。大多数情况下,RDS实例的CPU使用率低于1%,当我用100个同时调用的API对其进行测试时,它的使用率达到了5%,所以这不是瓶颈。内存也很好,所以我想RDS实例不会开始交换,这可能会减慢整个进程。
提供了确凿的证据,DEV环境上的(较小的)公共API调用目前需要2.30加载,而在PROD环境上则需要4.86s。这很有趣,因为DEV环境在EC2和RDS中都有一个小得多的实例类型。所以基本上海龟在这里赢得了比赛。(如果您对这个API调用感兴趣,我很乐意通过PN与您共享它,但我不想发布到API调用的链接,即使它们基本上是公开的。)
结论
最后,它感觉(我故意说‘感觉’)在x天的使用之后/在一定数量的API调用之后,DB被阻塞了。不确定这是否是一个特定于RDS的问题,一旦我通过更改实例类型“很大程度”地重置DB实例,事情就会运行得很快和顺利。但是,每两周从快照中重新创建我的DB实例不是一个选项,尤其是如果我不明白为什么会发生这种情况的话。
你知道我还能采取什么措施来调查这件事吗?
回答 3
Stack Overflow用户
发布于 2017-01-24 23:39:16
我知道你查过很多东西,但我想用另一种眼光来看.
请提供
SHOW VARIABLES; (probably need post.it or something, due to size)
SHOW GLOBAL STATUS;
how much RAM? Sounds like 7.5G
The query. -- Unclear what query/queries you are using
SHOW CREATE TABLE for the table(s) in the query -- indexes, datatypes, etc(上述一些问题可能有助于解决“随着时间推移而堵塞”的问题。)
同时,这里有一些猜测/问题/等等..。
- 其他一些共享硬件的客户也很忙。
- 可能是网络问题?
- 将
long_query_time缩小到1,这样就可以捕获慢速查询。 - 什么时候在您的实例上完成备份?
- 4s-18s加载一个兆字节--其中SQL语句的百分比是多少?
- 你“批次”插入吗?是单笔交易吗?是否同时进行冗长的询问?
- 如果有的话,您从AWS默认值中更改了哪些MySQL可调参数?
- 在7.5GB分区上的6GB buffer_pool?听起来很危险。你能看看有没有交换吗?
- 有涉及到
PARTITIONing吗?(当然,CREATE会回答这个问题。)
Stack Overflow用户
发布于 2017-01-29 03:16:09
您的描述中缺少一个非常重要的信息:数据库的总分配空间。RDS的I/O大约是分配空间的3倍,所以对于100 is的分配,您应该得到大约300 IOPS。分配的空间还包括日志。
由于您并不真正知道发生了什么,第一步应该是启动详细的监视,这将使您更多地了解实例上正在发生的事情。
在减速期间收集更多的统计数据之前,您可以尝试增加分配的空间,这将增加IOPS可用的值。
此外,检查事件中的db -日志是否定期被清除?这可能表明没有足够的空间。
最后,如果您知道应用程序需要什么,可以尝试使用PIOPS (供应IOPS),不过在这一点上听起来只是猜测。
Stack Overflow用户
发布于 2017-02-03 16:45:38
也许你的信贷余额已经(慢慢)耗尽了?最后,您将获得基线性能,这可能会显得“太慢”。
这也解释了为什么升级到另一种实例类型确实有帮助,因为您将重新开始完全突发平衡。
我建议增加音量的大小,即使你不需要额外的空间,当基线性能随体积大小线性增长时。
https://stackoverflow.com/questions/41218973
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号