
计算着色共享内存包含工件
我一直在尝试写一个通用的计算阴影,高斯模糊的隐写。
它基本上可以工作,但是它包含的工件可以改变每一个帧,即使场景是静态的。我花了几个小时来调试这个。我已经做到了确保不超过边界,展开所有循环,用常量替换制服,但是工件仍然存在。
我在3台不同的机器/GPU(2个nvidia,1个英特尔)上测试了原始代码,它们都产生了相同的结果。模拟使用使用普通C++代码向前和向后执行的工作组执行的代码的展开/常量版本不会产生这些错误。
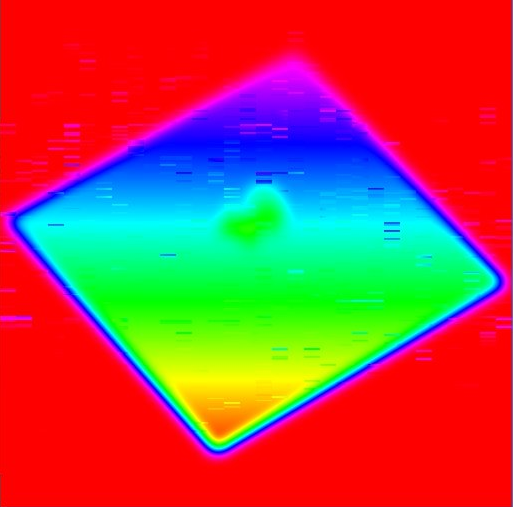
通过分配一个96而不是16的共享数组,我可以消除大部分工件。
这让我觉得我错过了一个逻辑错误,所以我成功地制作了一个非常简单的着色器,它仍然在较小的范围内产生错误,如果有人能指出原因,我会很感激的。我查过很多文件,没有发现任何不正确的地方。
分配一个16x48浮点数的共享数组,这是3072字节,大约是最小共享内存限制的10%。
着色器是在16x16工作组中启动的,因此每个线程将写入3个唯一的位置,并从一个唯一的位置读取数据。
纹理将呈现为HSV,0-1之间的值将映射为0-360色调(红色-青色-红色),超出界限的值将为红色。
#version 430
//Execute in 16x16 sized thread blocks
layout(local_size_x=16,local_size_y=16) in;
uniform layout (r32f) restrict writeonly image2D _imageOut;
shared float hoz[16][48];
void main ()
{
//Init shared memory with a big out of bounds value we can identify
hoz[gl_LocalInvocationID.x][gl_LocalInvocationID.y] = 20000.0f;
hoz[gl_LocalInvocationID.x][gl_LocalInvocationID.y+16] = 20000.0f;
hoz[gl_LocalInvocationID.x][gl_LocalInvocationID.y+32] = 20000.0f;
//Sync shared memory
memoryBarrierShared();
//Write the values we want to actually read back
hoz[gl_LocalInvocationID.x][gl_LocalInvocationID.y] = 0.5f;
hoz[gl_LocalInvocationID.x][gl_LocalInvocationID.y+16] = 0.5f;
hoz[gl_LocalInvocationID.x][gl_LocalInvocationID.y+32] = 0.5f;
//Sync shared memory
memoryBarrierShared();
//i=0,8,16 work
//i=1-7,9-5,17 don't work (haven't bothered testing further
const int i = 17;
imageStore(_imageOut, ivec2(gl_GlobalInvocationID.xy), vec4(hoz[gl_LocalInvocationID.x][gl_LocalInvocationID.y+i]));
//Sync shared memory (can't hurt)
memoryBarrierShared();
}以大于8x8的发射尺寸启动此着色器会在图像的受影响区域产生伪影。
glDispatchCompute(9, 9, 0); glMemoryBarrier(GL_SHADER_IMAGE_ACCESS_BARRIER_BIT);
我不得不用断点和步长帧来捕捉这个,大约有14帧。

glDispatchCompute(512/16, 512/16, 0);//Full image is 512x512 glMemoryBarrier(GL_SHADER_IMAGE_ACCESS_BARRIER_BIT);
同样,当运行在60 and (vsync)工件时,我不得不断点和步骤帧来捕获它。

回答 1
Stack Overflow用户
发布于 2016-12-16 01:37:07
memoryBarrierShared();
不,这只会使写入对其他调用可见。如果希望能够从其他调用的数据中读取数据,则必须确保所有的写操作都已经发生。
这是用 function完成的。它应该在memoryBarrierShared之后调用。
https://stackoverflow.com/questions/41175954
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号