
为什么np.where比pd.apply快
为什么np.where比pd.apply快
提问于 2016-12-15 14:16:34
示例代码在这里
import pandas as pd
import numpy as np
df = pd.DataFrame({'Customer' : ['Bob', 'Ken', 'Steve', 'Joe'],
'Spending' : [130,22,313,46]})
#[400000 rows x 4 columns]
df = pd.concat([df]*100000).reset_index(drop=True)
In [129]: %timeit df['Grade']= np.where(df['Spending'] > 100 ,'A','B')
10 loops, best of 3: 21.6 ms per loop
In [130]: %timeit df['grade'] = df.apply(lambda row: 'A' if row['Spending'] > 100 else 'B', axis = 1)
1 loop, best of 3: 7.08 s per loop回答 2
Stack Overflow用户
回答已采纳
发布于 2016-12-15 14:21:26
我认为np.where更快,因为使用numpy数组矢量化的方式,熊猫是在这个数组上构建的。
df.apply速度慢,因为它使用loops。
vectorize操作最快,其次是cython routines,然后是apply。
看这个回答,更好地解释熊猫开发者-杰夫。
Stack Overflow用户
发布于 2016-12-15 14:39:45
只是在所说的内容中添加了一种可视化方法。
df.apply的概况和总累积时间:
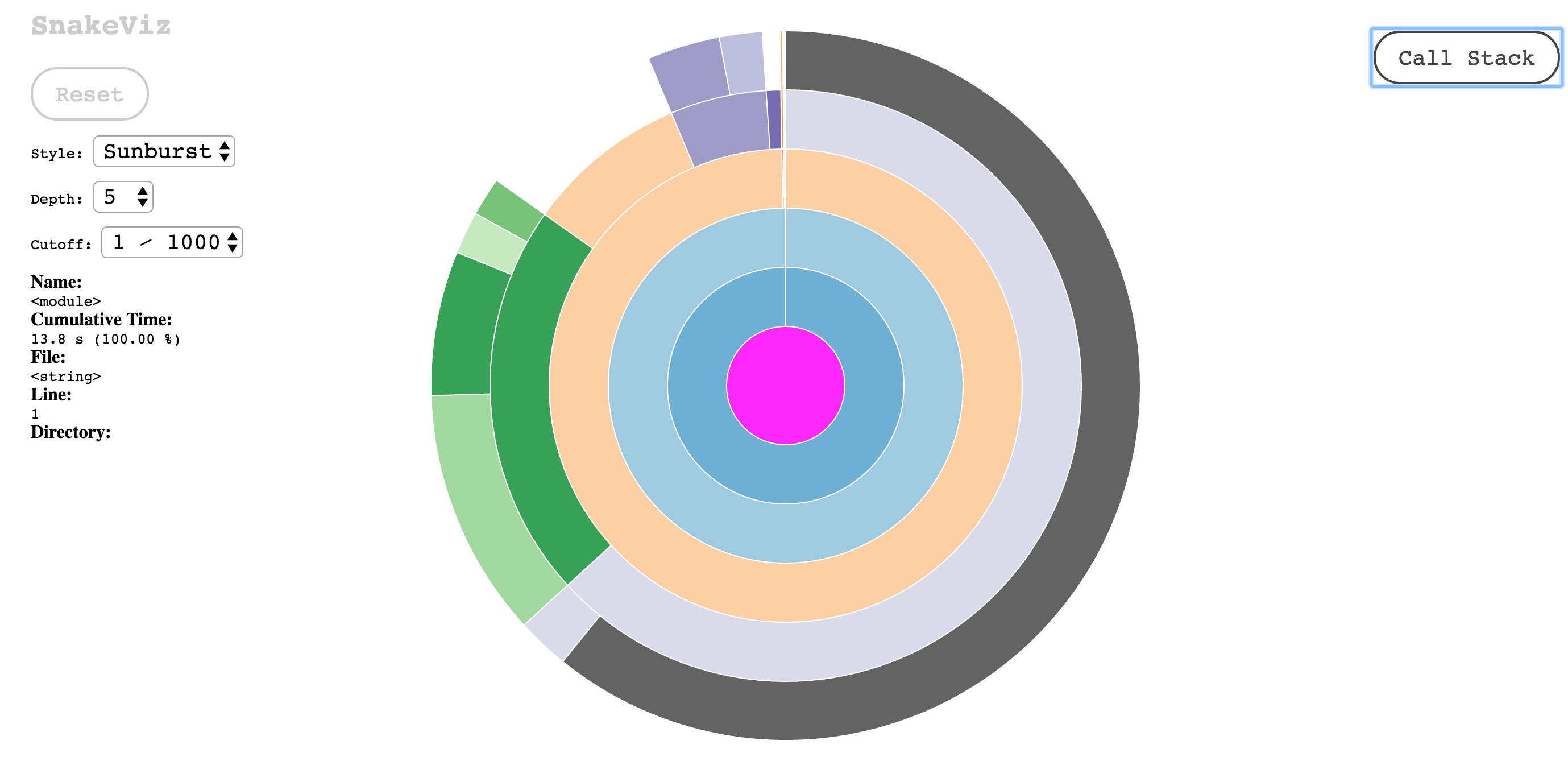
我们可以看到,时间是13.8s。
np.where的概况和总累积时间:
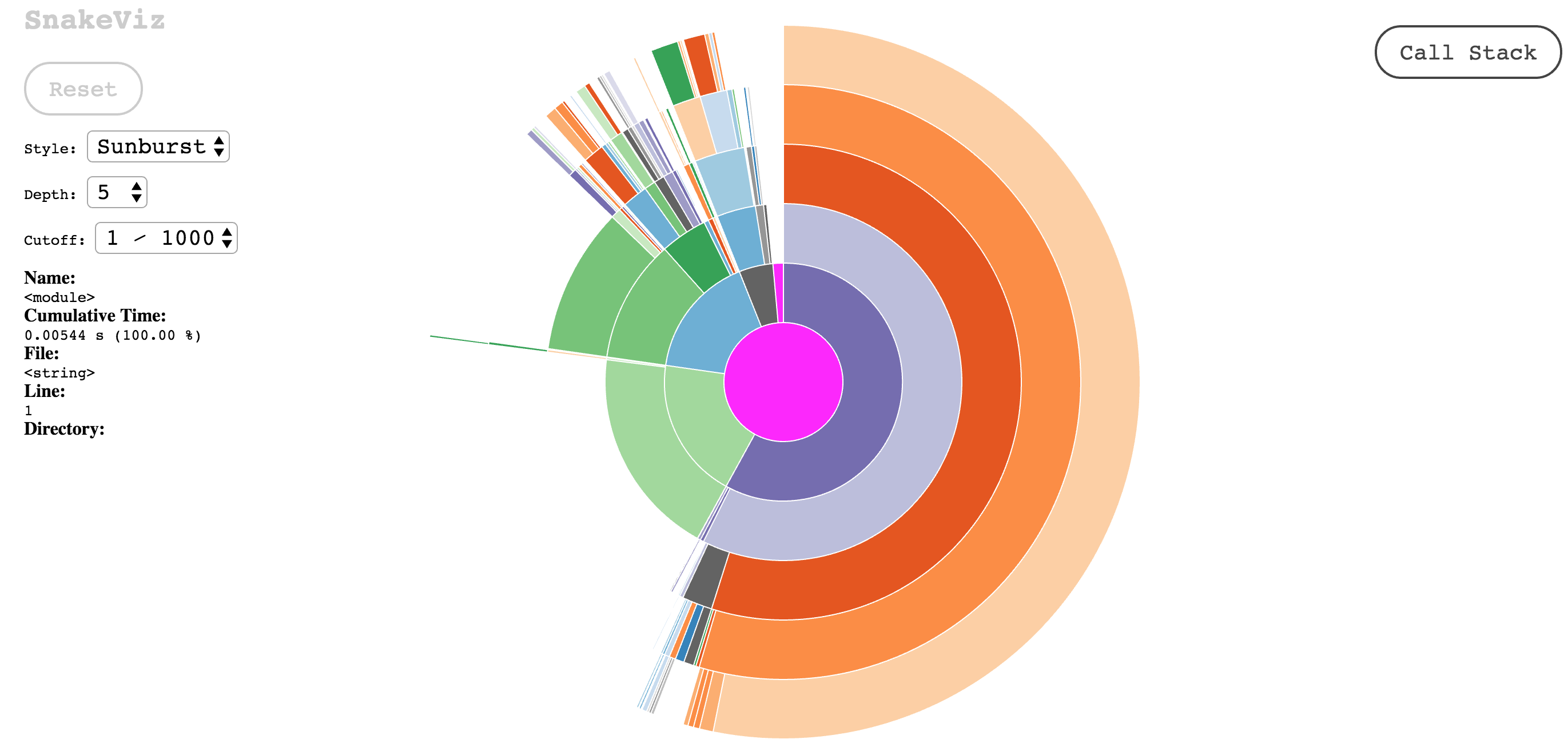
这里的累积时间是5.44ms,它比df.apply快2500倍
上面的图形是通过库snakeviz获得的。这里是指向库的链接。
SnakeViz将配置文件显示为阳光暴晒,其中函数表示为弧。根函数是中间的一个圆,它调用的函数,然后这些函数调用,以此类推。函数内部所花费的时间以弧的角度宽度表示。环绕圆圈的弧线代表一个函数,它占用了调用函数的大部分时间,而瘦弧线则代表一个几乎不需要任何时间的函数。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/41166348
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号