
如何解冻熊猫的数据
我有一个数据,如下所示,我想保留一个最好的评级列在这里。
原始DataFrame:
skunumber category overallrating rating reviews
123 Cat1 1 1 20
124 cat1 2 2 23为此,我正在融化数据,并将其重命名为“评级”。最后,如果有重复的话,我想再一次转换融化的数据帧原始格式。
熔化的Dataframe看起来如下:
skunumber category attribute attributeRawValue
123 Cat1 overallrating 1
124 cat1 overallrating 3
123 Cat1 rating 1
124 cat1 rating 2
123 Cat1 reviews 20
124 cat1 reviews 23DataFrame看起来就像在重命名之后,将总体重命名为评级和删除重复的。
skunumber category attribute attributeRawValue
123 Cat1 rating 1
124 cat1 rating 2
123 Cat1 reviews 20
124 cat1 reviews 23最后,我想要数据作为原始数据。
skunumber category rating reviews
123 Cat1 1 20
124 cat1 2 23我试着用pivot选项来执行这个操作,如果我们有一个索引列,但是这里有两个列,这是可行的。
样本代码:
messy = pd.DataFrame({'row' : ['A', 'B', 'C'],
'a' : [1, 2, 3],
'b' : [4, 5, 6],
'c' : [7, 8, 9]})
tidy = pd.melt(messy, id_vars='row', var_name='dimension',value_name='length')
messy1 = tidy.pivot(index='row',columns='dimension',values='length')
messy1.reset_index(inplace=True)
messy1.columns.name = '' 在我的例子中,我试图将索引传递为“skunumber”,“分类”--它不起作用
谢谢
回答 2
Stack Overflow用户
发布于 2016-12-14 12:22:53
我认为您需要在参数id_vars中添加另一列( melt )
df = df.rename(columns={'overallrating':'rating'})
tidy = pd.melt(df,
id_vars=['skunumber','category'],
var_name='dimension',
value_name='length')
tidy = tidy.drop_duplicates()
print (tidy)
skunumber category dimension length
0 123 Cat1 rating 1
1 124 cat1 rating 2
4 123 Cat1 reviews 20
5 124 cat1 reviews 23
messy1 = tidy.set_index(['skunumber','category','dimension'])
.length
.unstack()
.reset_index()
messy1.columns.name = None
print (messy1)
skunumber category rating reviews
0 123 Cat1 1 20
1 124 cat1 2 23使用stack、drop_duplicates (默认情况下只保留first值)和最后一个unstack的另一个更简单的解决方案
df = df.rename(columns={'overallrating':'rating'})
tidy = df.set_index(['skunumber','category'])
.stack()
.drop_duplicates()
.unstack()
.reset_index()
print (tidy)
skunumber category rating reviews
0 123 Cat1 1 20
1 124 cat1 2 23如果使用实际数据,您可以很容易地获得:
ValueError:索引包含重复条目,无法重新构造
然后,解决办法是低声或另一个答案:
df = pd.DataFrame({'category': ['Cat1', 'Cat1', 'cat1'],
'overallrating': [1, 5, 3],
'skunumber': [123, 123, 124],
'reviews': [20, 30, 23],
'rating': [4, 2, 2]})
print (df)
category overallrating rating reviews skunumber
0 Cat1 1 4 20 123
1 Cat1 5 2 30 123
2 cat1 3 2 23 124groupby按列创建新的index (此处为skunumber和category),并聚合一些函数,如mean、sum、max、min、first.
df = df.rename(columns={'overallrating':'rating'})
tidy = df.groupby(['skunumber','category'])['rating'].max().unstack().reset_index()
print (tidy)
skunumber category rating rating
0 123 Cat1 5 4
1 124 cat1 3 2评论编辑:
如果重复需要一些聚合函数,如max、first、sum、mean和groupby
print (df)
skunumber category overallrating rating reviews color colorShade
0 123 Cat1 1 1 12 White Red
1 123 Cat1 1 4 20 Pink Green
2 124 cat1 2 2 23 Black Blue
df = df.rename(columns={'overallrating':'rating', 'colorShade':'color'})
g = df.groupby(['skunumber','category'])
tidy1 = g['rating'].max().unstack()
print (tidy1)
rating rating
skunumber category
123 Cat1 1 4
124 cat1 2 2
tidy2 = g['color'].first().unstack()
print (tidy2)
color color
skunumber category
123 Cat1 White Red
124 cat1 Black Blue然后将concat数据放在一起:
df = pd.concat([tidy1, tidy2],axis=1).reset_index()
print (df)
skunumber category rating rating color color
0 123 Cat1 1 4 White Red
1 124 cat1 2 2 Black Blue另一种使用pd.lreshape的解决方案
tidy = pd.lreshape(df, {'rating':['rating','overallrating'], 'color':['color','colorShade']})
print (tidy)
category reviews skunumber color rating
0 Cat1 1 123 White 1
1 Cat1 20 123 Pink 4
2 cat1 23 124 Black 2
3 Cat1 1 123 Red 1
4 Cat1 20 123 Green 1
5 cat1 23 124 Blue 2
tidy = tidy.drop_duplicates(['category','skunumber'])
print (tidy)
category reviews skunumber color rating
0 Cat1 1 123 White 1
2 cat1 23 124 Black 2Stack Overflow用户
发布于 2016-12-14 12:32:07
您需要pivot_table来集成多个对象,因为它是index参数。但是,请注意,如果有与这些索引集相对应的重复值,则它们的聚合将产生默认情况下的平均值(aggfunc=np.mean)。如果您想要对这些值进行求和,则需要通过提供aggfunc=np.sum来具体地这样做。
piv_df = df.pivot_table(index=['skunumber', 'category'], columns=['attribute'], values=['attributeRawValue'])
piv_df.columns = piv_df.columns.droplevel(0)
piv_df.reset_index().rename_axis(None, 1)
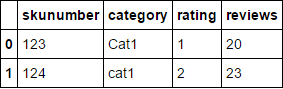
获得df
data = StringIO(
'''
skunumber category overallrating rating reviews
123 Cat1 1 1 20
124 cat1 2 2 23
''')
df = pd.read_csv(data, delim_whitespace=True)
df = pd.melt(df, id_vars=['skunumber', 'category'],
var_name='attribute', value_name='attributeRawValue')
df.loc[df['attribute']=='overallrating', 'attribute'] = 'rating'
df.drop_duplicates()
https://stackoverflow.com/questions/41142372
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号