
R-输出图包,包括网格线或轮廓线
我做了一个桑基图在R河图(v0.5),输出看起来很小在RStudio,但当输出或放大它的颜色有黑暗的轮廓或网格线。
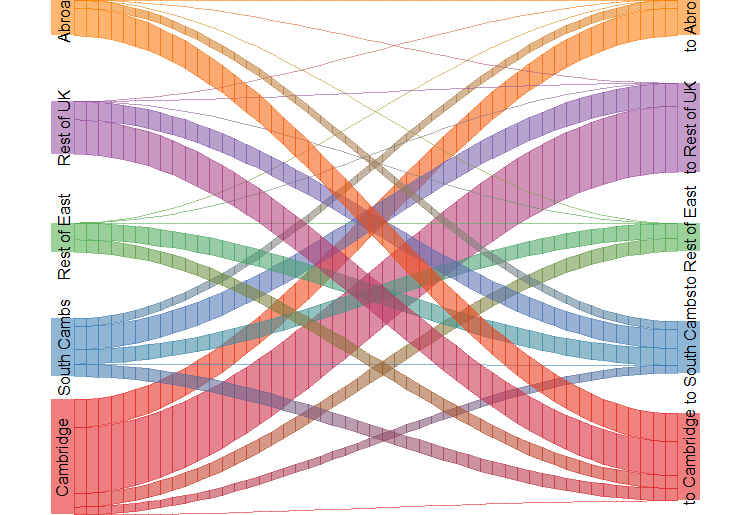
我认为这可能是因为形状的轮廓与我想用来填充的透明度不匹配?
我可能需要找到一种方法来完全消除轮廓(而不是使它们半透明),因为我认为它们也是为什么值为零的流仍然显示为细线的原因。
我的密码在这里:
#loading packages
library(readr)
library("riverplot", lib.loc="C:/Program Files/R/R-3.3.2/library")
library(RColorBrewer)
#loaing data
Cambs_flows <- read_csv("~/RProjects/Cambs_flows4.csv")
#defining the edges
edges = rep(Cambs_flows, col.names = c("N1","N2","Value"))
edges <- data.frame(edges)
edges$ID <- 1:25
#defining the nodes
nodes <- data.frame(ID = c("Cambridge","S Cambs","Rest of E","Rest of UK","Abroad","to Cambridge","to S Cambs","to Rest of E","to Rest of UK","to Abroad"))
nodes$x = c(1,1,1,1,1,2,2,2,2,2)
nodes$y = c(1,2,3,4,5,1,2,3,4,5)
#picking colours
palette = paste0(brewer.pal(5, "Set1"), "90")
#plot styles
styles = lapply(nodes$y, function(n) {
list(col = palette[n], lty = 0, textcol = "black")
})
#matching nodes to names
names(styles) = nodes$ID
#defining the river
r <- makeRiver( nodes, edges,
node_labels = c("Cambridge","S Cambs","Rest of E","Rest of UK","Abroad","to Cambridge","to S Cambs","to Rest of E","to Rest of UK","to Abroad"),
node_styles = styles)
#Plotting
plot( r, plot_area = 0.9)我的数据在这里
dput(Cambs_flows)
structure(list(N1 = c("Cambridge", "Cambridge", "Cambridge",
"Cambridge", "Cambridge", "S Cambs", "S Cambs", "S Cambs", "S Cambs",
"S Cambs", "Rest of E", "Rest of E", "Rest of E", "Rest of E",
"Rest of E", "Rest of UK", "Rest of UK", "Rest of UK", "Rest of UK",
"Rest of UK", "Abroad", "Abroad", "Abroad", "Abroad", "Abroad"
), N2 = c("to Cambridge", "to S Cambs", "to Rest of E", "to Rest of UK",
"to Abroad", "to Cambridge", "to S Cambs", "to Rest of E", "to Rest of UK",
"to Abroad", "to Cambridge", "to S Cambs", "to Rest of E", "to Rest of UK",
"to Abroad", "to Cambridge", "to S Cambs", "to Rest of E", "to Rest of UK",
"to Abroad", "to Cambridge", "to S Cambs", "to Rest of E", "to Rest of UK",
"to Abroad"), Value = c(0L, 1616L, 2779L, 13500L, 5670L, 2593L,
0L, 2975L, 4742L, 1641L, 2555L, 3433L, 0L, 0L, 0L, 6981L, 3802L,
0L, 0L, 0L, 5670L, 1641L, 0L, 0L, 0L)), class = c("tbl_df", "tbl",
"data.frame"), row.names = c(NA, -25L), .Names = c("N1", "N2",
"Value"), spec = structure(list(cols = structure(list(N1 = structure(list(), class = c("collector_character",
"collector")), N2 = structure(list(), class = c("collector_character",
"collector")), Value = structure(list(), class = c("collector_integer",
"collector"))), .Names = c("N1", "N2", "Value")), default = structure(list(), class = c("collector_guess",
"collector"))), .Names = c("cols", "default"), class = "col_spec"))回答 2
Stack Overflow用户
发布于 2017-02-16 20:11:42
罪魁祸首是riverplot::curveseg中的一条线。我们可以破解这个函数来修复它,或者有一个非常简单的解决方法,不需要对函数进行黑客攻击。事实上,在很多情况下,简单的解决方案可能是最好的,但是首先我解释如何破解这个函数,所以我们理解为什么这个解决方案也能工作。如果只想要简单的解决方案,可以滚动到这个答案的末尾:
更新:下面建议的更改现在已在河网版本0.6中实现
若要编辑该函数,可以使用
trace(curveseg, edit=T)然后在函数末尾附近找到一行,该行将读取
polygon(c(xx[i], xx[i + 1], xx[i + 1], xx[i]), c(yy[i],
yy[i + 1], yy[i + 1] + w, yy[i] + w), col = grad[i],
border = grad[i])我们在这里可以看到,包作者选择不将lty参数传递给polygon (有关为什么包作者这样做的解释,请参见this answer )。通过添加lty = 0 (或者,如果您愿意的话,也可以添加border = NA)来更改这一行,并且它的工作原理与OPs情况一样。(但请注意,如果您希望呈现一个pdf -请参阅here),这可能不太好。
polygon(c(xx[i], xx[i + 1], xx[i + 1], xx[i]), c(yy[i],
yy[i + 1], yy[i + 1] + w, yy[i] + w), col = grad[i],
border = grad[i], lty=0)

顺便提一句,这也解释了在评论中所报道的一些奇怪的行为:“如果你运行它两次,那么情节第二次看起来还可以,尽管导出它并返回行”。当在对lty的调用中未指定polygon时,它使用的默认值是lty = par("lty")。最初,默认的par("lty")是一个实线,但是在运行了一次江河绘图函数之后,在调用riverplot:::draw.nodes时,par("lty")会被设置为0,从而在第二次运行riverplot时抑制这些行。但是,如果然后尝试导出图像,打开一个新设备将par("lty")重置为默认值。
使用此编辑更新函数的另一种方法是使用assignInNamespace用自己的版本覆盖包函数。如下所示:
curveseg.new = function (x0, x1, y0, y1, width = 1, nsteps = 50, col = "#ffcc0066",
grad = NULL, lty = 1, form = c("sin", "line"))
{
w <- width
if (!is.null(grad)) {
grad <- colorRampPaletteAlpha(grad)(nsteps)
}
else {
grad <- rep(col, nsteps)
}
form <- match.arg(form, c("sin", "line"))
if (form == "sin") {
xx <- seq(-pi/2, pi/2, length.out = nsteps)
yy <- y0 + (y1 - y0) * (sin(xx) + 1)/2
xx <- seq(x0, x1, length.out = nsteps)
}
if (form == "line") {
xx <- seq(x0, x1, length.out = nsteps)
yy <- seq(y0, y1, length.out = nsteps)
}
for (i in 1:(nsteps - 1)) {
polygon(c(xx[i], xx[i + 1], xx[i + 1], xx[i]),
c(yy[i], yy[i + 1], yy[i + 1] + w, yy[i] + w),
col = grad[i], border = grad[i], lty=0)
lines(c(xx[i], xx[i + 1]), c(yy[i], yy[i + 1]), lty = lty)
lines(c(xx[i], xx[i + 1]), c(yy[i] + w, yy[i + 1] + w), lty = lty)
}
}
assignInNamespace('curveseg', curveseg.new, 'riverplot', pos = -1, envir = as.environment(pos))现在用于简单的解决方案,它不需要更改函数:
只需添加行par(lty=0)之前,你的阴谋!
Stack Overflow用户
发布于 2017-02-17 09:36:24
这是这个包的作者。我现正努力寻求一个令人满意的解决办法,以便将其纳入下一版本的一揽子方案。
问题在于与位图相比,R是如何呈现PDF的。在包的原始版本中,我确实将lty=0传递给polygon() (您仍然可以在注释的源代码中看到它)。但是,多边形w/o边框只在png图形上看起来很好。在pdf输出中,多边形之间会出现细白线。看一看:
cc <- "#E41A1C90"
plot.new()
rect(0.2, 0.2, 0.4, 0.4, col=cc, border=NA)
rect(0.4, 0.2, 0.6, 0.4, col=cc, border=NA)
dev.copy2pdf(file="riverplot.pdf")在X或png中,输出是正确的。但是,如果呈现为PDF格式,您将看到两个直角之间有一条细白线:

当您将河图图形呈现为像上面那样的PDF格式时,这看起来非常糟糕:
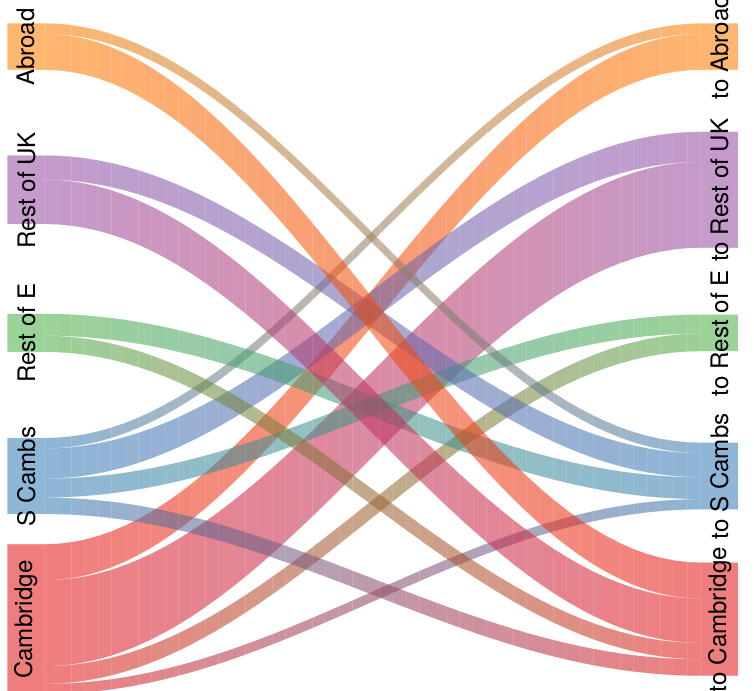
因此,我被迫增加边界,但忘记了检查透明度。当不使用透明性时,这看起来没问题--边框和多边形重叠,而且彼此重叠,但你看不到它。PDF现在是可以接受的。然而,如果你有透明度的话,它会把数字搞砸。
编辑:
我现在已经上传了版本0.6的江河图到CRAN。除了一些新的东西(您现在可以将河网添加到现有绘图的任何部分),默认情况下,它再次使用lty=0。但是,现在有一个名为"fix.pdf“的选项,您可以将其设置为TRUE,以便再次在段周围绘制边框。
底线,以及目前的解决方案:
- 利用河岸0.6`
- 如果要呈现PDF格式,请不要使用透明度,而要使用fix.pdf=TRUE
- 如果您想同时使用透明度和PDF,请帮助我解决这个问题。
https://stackoverflow.com/questions/41088751
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号