
在Windows上安装sparklyr
我尝试过几个关于在Windows环境中设置Spark和Hadoop的教程,特别是在R. 这一个旁边,在我访问图9时导致了这个错误:

本教程来自Rstudio也给了我一些问题。当我到达
sc <- spark_connect(master = "local")
步骤,我得到了一个熟悉的错误:
Error in force(code) :
Failed while connecting to sparklyr to port (8880) for sessionid (1652): Gateway in port (8880) did not respond.
Path: C:\Users\jvangeete\spark-2.0.2-bin-hadoop2.7\bin\spark-submit2.cmd
Parameters: --class, sparklyr.Backend, "C:\Users\jvangeete\Documents\R\win-library\3.3\sparklyr\java\sparklyr-2.0-2.11.jar", 8880, 1652
---- Output Log ----
The system cannot find the path specified.
---- Error Log ----这个端口问题与我尝试在"yarn-client"中分配spark_connect(...)参数时所遇到的问题类似,也是在Zaidi女士的教程这里中尝试时遇到的。(该教程有自己的问题,如果有人感兴趣的话,我会把它放在一个名为这里的板上。)
如果我第一次安装Ubuntu,TutorialsPoint演练可以帮助我完成任务,但是我使用的是Microsoft (RO),所以我想在Windows中解决这个问题,尤其是因为Emaasit先生似乎在第一个教程中就能够运行.\bin\sparkR无法运行的命令。
一般情况下,我试图了解如何在Windows中使用sparklyr来安装和运行Spark和R。
更新1:这是目录中的内容:
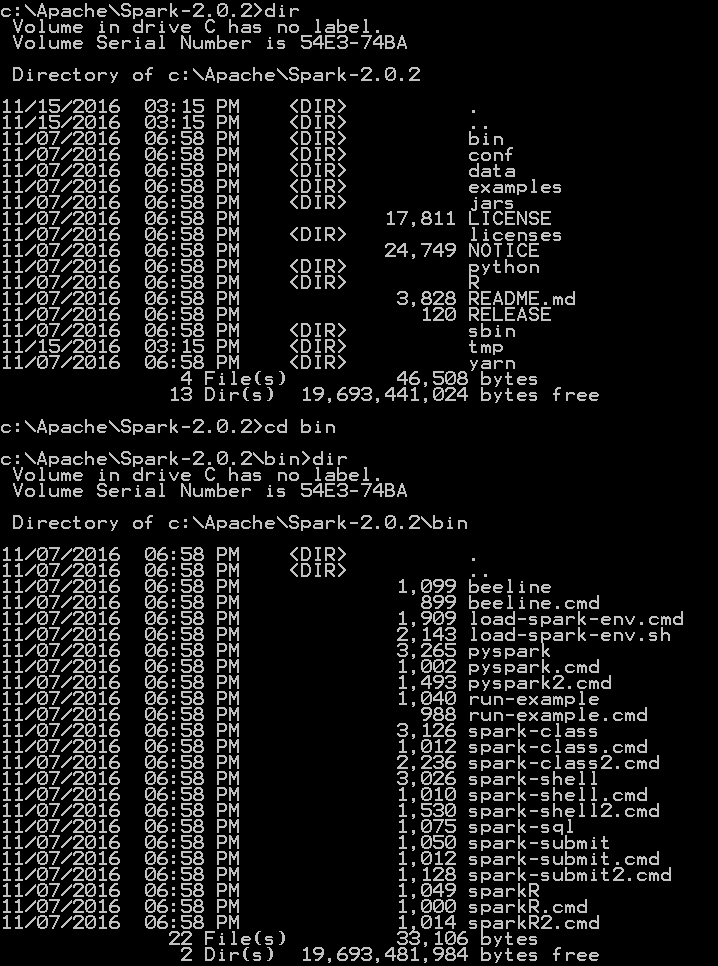
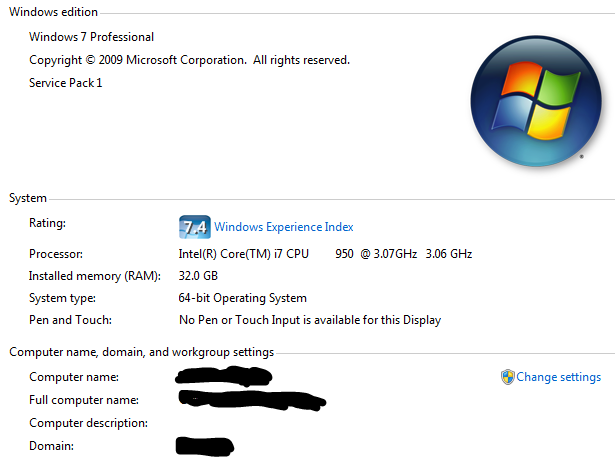
更新2:这是我的R-会话和系统信息
platform x86_64-w64-mingw32
arch x86_64
os mingw32
system x86_64, mingw32
status
major 3
minor 3.1
year 2016
month 06
day 21
svn rev 70800
language R
version.string R version 3.3.1 (2016-06-21)
nickname Bug in Your Hair
回答 1
Stack Overflow用户
发布于 2017-05-11 05:24:54
- 从spark_hadoop下载http://spark.apache.org/downloads.html tar
- 从carn上安装sparklyr软件包
- spark_install_tar(tarfile = "path/to/spark_hadoop.tar")
如果仍然有错误,则手动解压缩tar,并将spark_home环境变量点设置为spark_hadoop untar路径。
然后在R控制台中尝试执行以下命令。库(Sparklyr) sc <- spark_connect(master = "local")。
https://stackoverflow.com/questions/40642348
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号