
减少SQL查询的执行时间
我有一个问题,在处理和提高查询效率的同时保持其准确性。在显示查询之前,我想指出一些基本知识。
我有一个案例,它操纵where-clause来获取父级的所有孩子。基本上,我有两种类型的数据需要显示:红色和绿色类型。默认情况下,红色类型的列(TRK_TrackerGroup_LKID2)设置为NULL,而绿色数据在该列中有一个值(范围从5-7)。
我的问题是,我需要提取两种类型的数据才能准确地获得视图中未决问题的计数,但是这样做(通过添加情况),执行时间从< 1秒到远远超过15秒。
这是查询(在上述情况下):
SELECT TS.id AS TrackerStartDateID,
TSM.mappingtypeid,
TSM.maptoid,
TFLK.trk_trackergroup_lkid,
Count(TF.id) AS Cnt
FROM [dbo].[trk_startdate] TS
INNER JOIN [dbo].[trk_startdatemap] TSM
ON TS.id = TSM.trk_startdateid
AND TSM.deletedflag = 0
INNER JOIN [dbo].[trk_trackerfeatures] TF
ON TF.trk_startdateid = TS.id
AND TF.deletedflag = 0
INNER JOIN [dbo].[trk_trackerfeatures_lk] TFLK
ON TFLK.id = TF.trk_feature_lkid
WHERE TS.deletedflag = 0
AND TF.applicabletoproject = 1
AND TF.readyforwork = CASE -- HERE IS THE PROBLEM
WHEN TF.trk_trackerstatus_lkid2 IS NULL THEN 0
ELSE 1
END
AND TF.datestamp = (SELECT Max(TF2.datestamp)
FROM [dbo].[trk_trackerfeatures] TF2
INNER JOIN [dbo].[trk_trackerfeatures_lk] TFLK2
ON TFLK2.id = TF2.trk_feature_lkid
WHERE TF.trk_startdateid = TF2.trk_startdateid
AND TFLK2.trk_trackergroup_lkid = TFLK.trk_trackergroup_lkid)
GROUP BY TS.id,
TSM.mappingtypeid,
TSM.maptoid,
TFLK.trk_trackergroup_lkid,
TF.datestamp 它具有“父”的功能,从每个子组中获取最新插入的数据集(使用DateStamp)。这对于稍后在SSRS报告中生成父报表是必要的,但目前我的问题(如上所述)是执行时间。
我想知道是否有关于如何在保持查询的准确性的同时减少执行时间的建议。
预期产出:

如果没有这个案子,我就明白了:
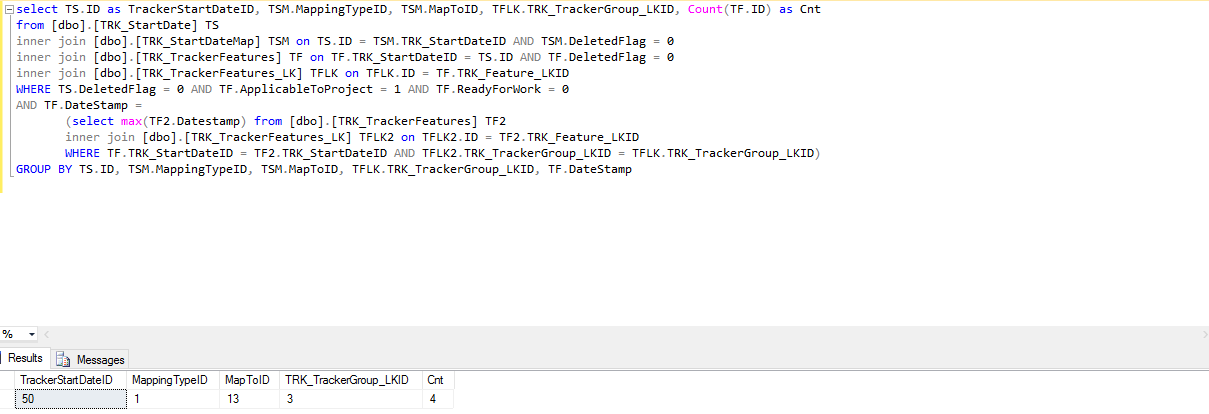
回答 2
Stack Overflow用户
发布于 2016-11-08 13:44:37
您的问题是这种情况不能使用INDEX
AND TF.readyforwork = CASE -- HERE IS THE PROBLEM
WHEN TF.trk_trackerstatus_lkid2 IS NULL THEN 0
ELSE 1
END试着把它改成
AND ( TF.readyforwork = 0 and TF.trk_trackerstatus_lkid2 IS NULL
OR TF.readyforwork = 1 and TF.trk_trackerstatus_lkid2 IS NOT NULL
)但是,您应该再次检查EXPLAIN ANALIZE,以测试您的查询是否使用索引。
Stack Overflow用户
发布于 2016-11-08 13:40:44
查询中最有问题的部分似乎是关联子查询,因为您必须为每个可能的行调用它。
您应该首先优化这一点。为此,可以添加引擎可用于快速计算每行的值的索引。
根据您的查询,我将添加以下两个索引倍数:
- 关于表
trackerfeatures,索引字段:trk_startdateid, datestamp - 关于表
trk_trackerfeatures_lk,索引字段:id, trk_trackergroup_lkid
https://stackoverflow.com/questions/40488116
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号