
对一组特征向量进行采样,以获得每个特征的“统一”直方图。
对一组特征向量进行采样,以获得每个特征的“统一”直方图。
提问于 2016-11-02 10:38:40
我有一个m向量(样本)的n个值(特征)的矩阵,其中m~ 10^6,n= 20,所有特征的值都在0,1。
如果我计算每个特征的直方图,它们是完全不同的。我计算了一个简单的10桶直方图,我可以看到,对于一些直方图,只有几个桶(甚至两个)包含所有样本,一些是倾斜高斯的,另一些是近似均匀的。
我想对这些向量中的一个子集进行采样,以便对所有的特征都有一个“均匀”分布。这基本上意味着,对于每个尚未为空的桶,我希望有大致相同数量的元素。该子集的合理最小元素为100。
我选择的语言是MATLAB,但我更感兴趣的是知道是否有我可以使用的算法,而不是实际的代码(我可以自己工作)。
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-11-02 14:14:53
一种方法是建立对每个特征的值分布的近似,或者拟合一个解析分布函数- and,然后对每个样本进行相应的加权。
vfNormValues = randn(1, 10000); % Samples from Normal distribution with mu=1, sigma=0
fMean = 0; mean(vfNormValues);
fStd = 1; std(vfNormValues);
vfWeights = 1./normpdf(vfNormValues, fMean, fStd); % Assume the underlying distribution is Normal
vfSamples = randsample(vfNormValues, 8000, true, vfWeights); % Weighted random sample with replacement
figure;
subplot(1, 2, 1);
hist(vfNormValues);
title('Original samples');
subplot(1, 2, 2);
hist(vfSamples);
title('Weighted re-sampling');
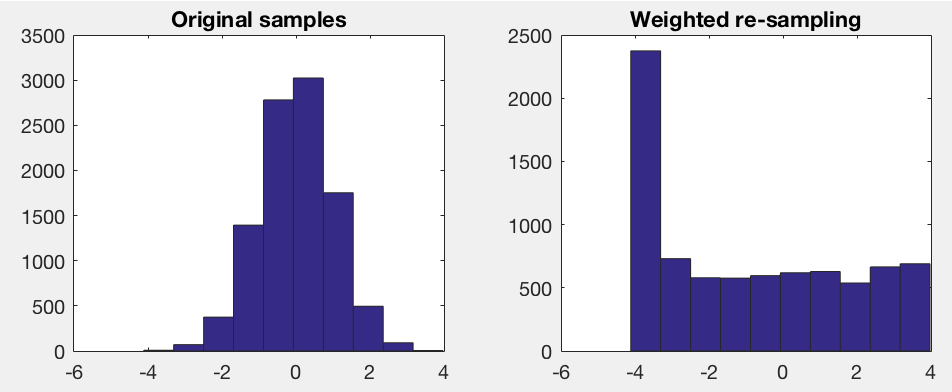
正如您所看到的,分析方法可能会导致异常值的过度抽样。
或者,您可以使用完全经验分布估计值,通过直方图:
nNumBins = floor(sqrt(numel(vfNormValues)));
[vnCounts, ~, vnBin] = histcounts(vfNormValues, nNumBins); % Set number of bins according to desired accuracy
vfBinWeights = 1./(vnCounts ./ sum(vnCounts));
vfWeights = vfBinWeights(vnBin);然后像以前一样,用替换的方法执行加权样本。
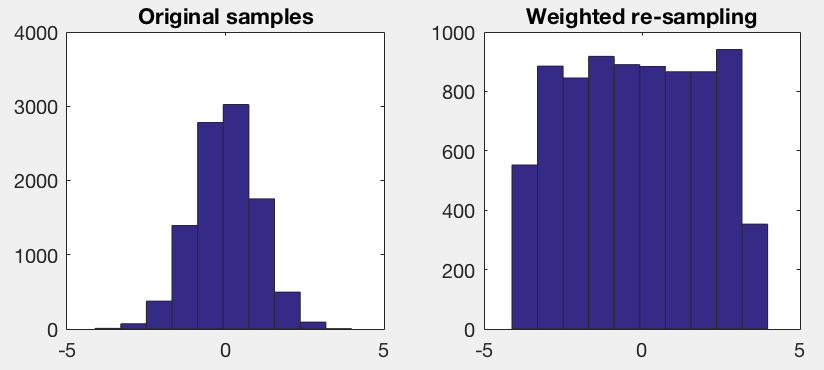
然后,您将需要研究如何为这几个特性组合发行版。在统计独立的假设下,您可以简单地结合每个特征的权重来使用边际分布。如果这些特征在统计上不是独立的,那么你必须构建一个20维的直方图.
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/40377861
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号