
BeautifulSoup:在元素中查找元素
BeautifulSoup:在元素中查找元素
提问于 2016-10-26 13:39:21
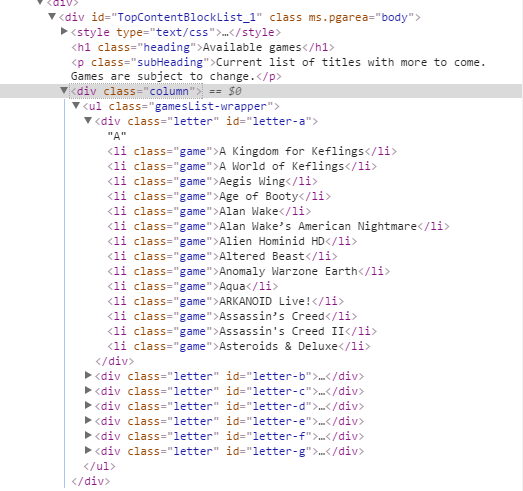
我试图从下面的网站在"a“类别下找到一个游戏列表。无论我尝试何种模式,我都可以找到具有值为“字母-a”的id属性的id,而不是直接在其中找到li元素。
import bs4
import logging
import requests
logging.basicConfig(level=logging.DEBUG, format="%(asctime)s - \
%(levelname)s - %(message)s")
##res = requests.get("http://www.xbox.com/en-GB/xbox-one/backward-\
##compatibility")
res = requests.get("http://www.xbox.com/en-US/xbox-one/backward-\
compatibility/available-games")
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "html.parser")
#game_elems = soup.select("body[id=\"DocumentBody\"] div[id=\"bodycolumn\"]")
game_elems = soup.select("#letter-a li")
logging.info("Length added elements: {}".format(len(game_elems)))
if game_elems:
logging.info("First element in 'game_elems': {}".format(str(game_elems[0])))
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-10-26 13:53:52
您可以通过使用Selenium控制浏览器来抓取由JS修改的DOM。要用Selenium来完成它,您可以这样做:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Firefox()
driver.get("http://www.xbox.com/en-US/xbox-one/backward-compatibility/available-games")
elem = driver.find_element_by_css_selector("#letter-a")
print elem.get_attribute('innerHTML')
driver.close()您还可以使用Selenium控制其他浏览器,包括无头浏览器(在后台运行的浏览器,而不打开窗口),如PhantomJS。
在此之前,我注意到HTML格式错误--您不应该在ul中直接使用一个HTML。但这并不是最后的阻塞问题。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/40263852
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号