
确定多模态单变量数据核密度估计的模式位置
如果我有一个密度函数,我用一个特定的带宽绘制它,我视觉上确定有7个局部最大值。我只想知道如何在同一地块上分别绘制特定极大值的分布。此外,如果可能的话,通过运行一些代码可以准确地知道最大值发生在哪里?我可以用这幅图来做公园的估计,但是有一个R函数,我可以用它来得到精确的点吗?我想知道我所确定的7种密度的平均值和方差。具体来说,我有以下几点:
plot(density(stamp, bw=0.0013,kernel = "gaussian")) 回答 3
Stack Overflow用户
发布于 2016-10-23 05:13:57
在内核密度估计中确定哪种模式是真实的,这取决于您选择使用哪种带宽。这是一件复杂的事情,我不建议选择一个带宽,因为即使是不同的最佳经验规则也能给出不同的答案。一般来说,kde的模式数小于过平滑情况下的底层密度数,而在欠光滑情况下则更多。有许多论文涵盖了这个主题,并为您提供了许多选项来帮助确定模式的准确性。例如,查看Silverman对高斯核的模式测试、Friedman和Fisher的prim算法、Marron的siZer以及Minnotte和Scott的模式树是很好的起点。
考虑到单一的KDE带宽选择,您可以做的一件天真的事情是检查运行长度。
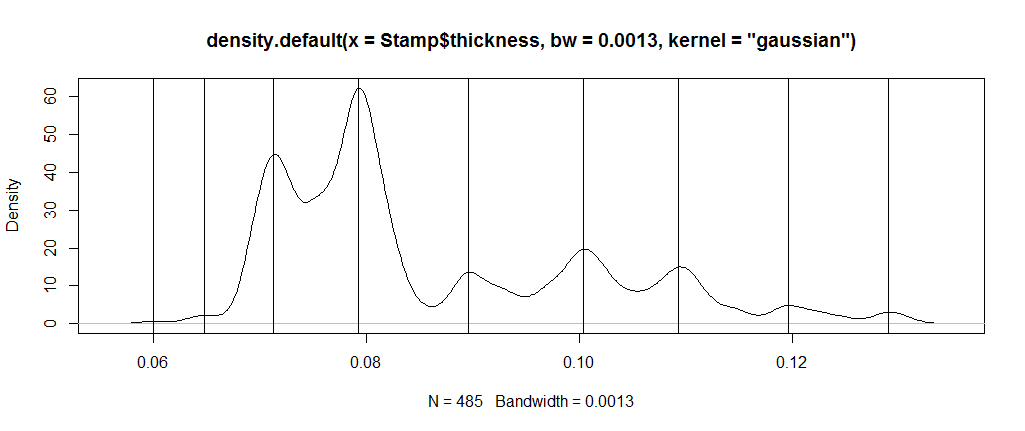
事实上,通过你选择的带宽,我发现了9种模式。只需计算序列中差值的符号变化,并计算跑步的累积长度,以便找到点。每一个其他的点将是模式或反模式,这取决于哪一个最先出现。(您可以检查标志以确定这一点)
library(BSDA)
dstamp <- density(Stamp$thickness, bw=0.0013, kernel = "gaussian")
chng <- cumsum(rle(sign(diff(dstamp$y)))$lengths)
plot(dstamp)
abline(v = dstamp$x[chng[seq(1,length(chng),2)]])
Stack Overflow用户
发布于 2020-10-02 18:08:48
因为我只需要一些东西才能得到最强的模式,所以我创建了一个简单的死算法,它允许您通过调整密度样本的数量(以消除局部噪声)来增加灵敏度,并设置一个与最大密度成正比的最小密度阈值(以降低全局噪声)。
find_posterior_modes <- function(x, n.samples = 100, filter = .1) {
d <- density(x, n = n.samples)
x <- with(d, sapply(2:(n.samples - 1), function(i) if (y[i] > y[i - 1] & y[i] > y[i + 1] & y[i] > max(y) * filter) x[i]))
unlist(x)
}https://stackoverflow.com/questions/40198674
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号