
从多索引数据框架中获取列值
从多索引数据框架中获取列值
提问于 2016-10-19 14:41:57
我有一个多索引数据框架如下所示:
1 2
panning sec panning sec
None 5.0 None 0.0
None 6.0 None 1.0
Panning 7.0 None 2.0
None 8.0 Panning 3.0
None 9.0 None 4.0
Panning 10.0 None 5.0我正在遍历行,并在窗格列中有一个值' panning‘的地方获得索引。
ide=[]
for index,row in dfs.iterrows():
if [row[:, 'Panning'][row[:, 'Panning'] == 'Panning']]:
ide.append(row[:, 'Panning'][row[:, 'Panning'] == 'Panning'].index.tolist())
print ide如果执行上述代码,就会得到输出。
[[],[],[1],[2],[],[1]],它表示值正在平移的索引。
现在,我还想得到相应的sec值,例如,对于第3行的值平移,我希望获得sec值7.0和索引1。
[[],[],[1,7.0],[2,3.0],[],[1,10]]基本上,我需要O/P作为索引的组合,其中值是摇摄的,而后面的值是秒列中的值。
回答 3
Stack Overflow用户
回答已采纳
发布于 2016-10-21 08:54:22
您可以使用:
print (dfs)
1 2
Panning sec Panning sec
0 None 5.0 None 0.0
1 None 6.0 None 1.0
2 Panning 7.0 None 2.0
3 None 8.0 Panning 3.0
4 None 9.0 None 4.0
5 Panning 10.0 None 5.0循环溶液
ide=[]
for index,row in dfs.iterrows():
if (row[:, 'Panning'] == 'Panning').any():
idx1 = row[:, 'Panning'][row[:, 'Panning'] == 'Panning'].index.tolist()
idx2 = row.loc[(idx1, 'sec')].values.tolist()[0]
idx1.append(idx2)
ide.append(idx1)
else:
ide.append([])
print (ide)
[[], [], ['1', 7.0], ['2', 3.0], [], ['1', 10.0]]叠加溶液
stacked = dfs.stack(0).reset_index(level=1)
mask = stacked['Panning'] == 'Panning'
L = stacked[mask].reindex(dfs.index).drop('Panning', axis=1).fillna('').values.tolist()
print (L)
[['', ''], ['', ''], ['1', 7.0], ['2', 3.0], ['', ''], ['1', 10.0]]
print ([x if not x == ['', ''] else [] for x in L])
[[], [], ['1', 7.0], ['2', 3.0], [], ['1', 10.0]]解释
#stacked top level of MultiIndex in column
#create column from 1. level of index values
stacked = dfs.stack(0).reset_index(level=1)
print (stacked)
level_1 Panning sec
0 1 None 5.0
0 2 None 0.0
1 1 None 6.0
1 2 None 1.0
2 1 Panning 7.0
2 2 None 2.0
3 1 None 8.0
3 2 Panning 3.0
4 1 None 9.0
4 2 None 4.0
5 1 Panning 10.0
5 2 None 5.0#boolean indexing
#http://pandas.pydata.org/pandas-docs/stable/indexing.html#boolean-indexing
mask = stacked['Panning'] == 'Panning'
print (mask)
0 False
0 False
1 False
1 False
2 True
2 False
3 False
3 True
4 False
4 False
5 True
5 False
Name: Panning, dtype: bool
print (stacked[mask])
level_1 Panning sec
2 1 Panning 7.0
3 2 Panning 3.0
5 1 Panning 10.0#reindex by original index, remove column Panning
print (stacked[mask].reindex(dfs.index).drop('Panning', axis=1))
level_1 sec
0 NaN NaN
1 NaN NaN
2 1 7.0
3 2 3.0
4 NaN NaN
5 1 10.0
#replace NaN to '' and generate list of list
L = stacked[mask].reindex(dfs.index).drop('Panning', axis=1).fillna('').values.tolist()
print (L)
[['', ''], ['', ''], ['1', 7.0], ['2', 3.0], ['', ''], ['1', 10.0]]
#replace empty lists by empty list
print ([x if not x == ['', ''] else [] for x in L])
[[], [], ['1', 7.0], ['2', 3.0], [], ['1', 10.0]]Stack Overflow用户
发布于 2016-10-19 15:33:35
考虑下面的设置参考中的pd.DataFrame df
方法1
- 截面
xs any(1)检查行内是否有
df.loc[df.xs('Panning', axis=1, level=1).eq('Panning').any(1)]
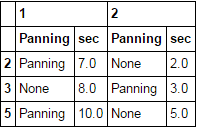
方法2
stackqueryunstack
df.stack(0).query('Panning == "Panning"').stack().unstack([-2, -1])
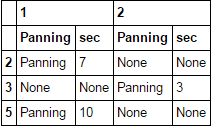
只返回sec列
df.xs('sec', axis=1, level=1)[df.xs('Panning', axis=1, level=1).eq('Panning').any(1)]
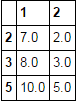
设置
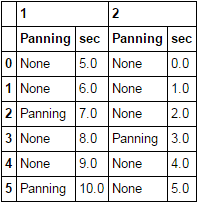
参考文献
from StringIO import StringIO
import pandas as pd
txt = """None 5.0 None 0.0
None 6.0 None 1.0
Panning 7.0 None 2.0
None 8.0 Panning 3.0
None 9.0 None 4.0
Panning 10.0 None 5.0"""
df = pd.read_csv(StringIO(txt), delim_whitespace=True, header=None)
df.columns = pd.MultiIndex.from_product([[1, 2], ['Panning', 'sec']])
df
Stack Overflow用户
发布于 2016-10-19 15:07:20
df.iterrows()返回一个Series,如果您想要原始的index,则需要调用该Series的name:
for index,row in df.iterrows():
print row.name页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/40134637
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号