
星系团和卡桑德拉的土卫六的设置和配置
aurelius邮件列表上已经有几个问题,还有关于stackoverflow配置Titan以使其与Spark一起工作的具体问题。但在我看来,缺少的是一个使用泰坦和星火的简单设置的高级描述。
我正在寻找的是一个使用推荐设置的稍微小的设置。例如,对于Cassandra,复制因子应该是3,并且应该使用一个专用的数据中心进行分析。
根据我在“星火”、“泰坦”和“卡桑德拉”的文档中发现的信息,这样的最小设置如下所示:
- 实时处理DC: 3个节点与土卫六+卡桑德拉(RF: 3)
- 分析DC: 1火种主+3火种奴隶与卡桑德拉(RF: 3)
关于这个设置和泰坦+星火,我有一些问题:
- 这个设置正确吗?
- 土卫六是否也应该安装在3个星火从节点和/或星火主节点上?
- 您是否会使用另一种设置?
- 星火奴隶是否只读取来自分析DC的数据,甚至从同一节点上的Cassandra读取数据?
也许有人甚至可以共享一个支持这种设置的配置文件(或者更好的配置文件)。
回答 1
Stack Overflow用户
发布于 2016-10-21 15:10:20
因此,我尝试了一下,并设置了一个简单的星火集群来与Titan (以及Cassandra作为存储后端)一起工作,下面是我想出的:
高级别概览
这里我只关注集群的分析方面,所以我释放了实时处理节点。
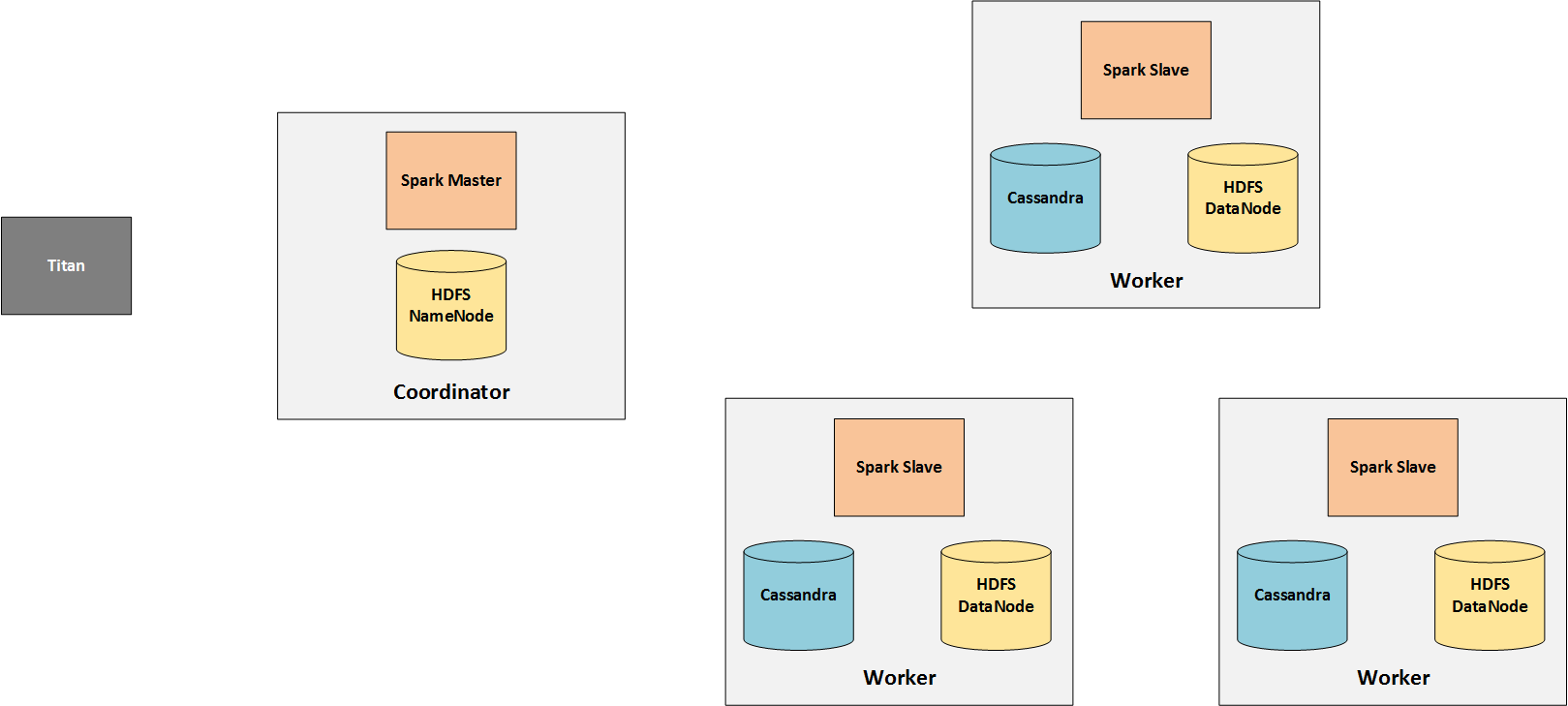
火花由一个(或多个)主人和多个奴隶(工人)组成。因为奴隶做实际的处理,他们需要访问他们工作的数据。因此,卡桑德拉安装在工人和保存从土卫六的图表数据。
工作是从土卫六节点发送到火花主,后者分配给他的工人。因此,泰坦基本上只与火种大师沟通。
之所以需要HDFS,只是因为TinkerPop在其中存储中间结果。注意,那个这在TinkerPop 3.2.0中发生了变化。。
安装
HDFS
我只是遵循了一个教程,我发现了这里。对于土卫六来说,这里只需要记住两件事:
- 选择兼容版本,对于Titan 1.0.0,这是1.2.1。
- 不需要来自Hadoop的TaskTrackers和JobTrackers,因为我们只需要HDFS,而不需要MapReduce。
火花
同样,版本必须兼容,对于Titan 1.0.0也是1.2.1。安装基本上意味着使用编译后的版本提取存档。最后,您可以通过导出应该指向Hadoop的conf目录的HADOOP_CONF_DIR来配置Spark来使用HDFS。
土卫六结构
您还需要在要从该节点启动OLAP作业的土卫六节点上设置一个HADOOP_CONF_DIR。它需要包含一个指定core-site.xml的NameNode文件:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://COORDINATOR:54310</value>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.</description>
</property>
</configuration>将HADOOP_CONF_DIR添加到CLASSPATH中,TinkerPop应该能够访问HDFS。TinkerPop文档包含更多有关这方面的信息,以及如何检查HDFS是否配置正确。
最后,一个为我工作的配置文件:
#
# Hadoop Graph Configuration
#
gremlin.graph=org.apache.tinkerpop.gremlin.hadoop.structure.HadoopGraph
gremlin.hadoop.graphInputFormat=com.thinkaurelius.titan.hadoop.formats.cassandra.CassandraInputFormat
gremlin.hadoop.graphOutputFormat=org.apache.tinkerpop.gremlin.hadoop.structure.io.gryo.GryoOutputFormat
gremlin.hadoop.memoryOutputFormat=org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat
gremlin.hadoop.deriveMemory=false
gremlin.hadoop.jarsInDistributedCache=true
gremlin.hadoop.inputLocation=none
gremlin.hadoop.outputLocation=output
#
# Titan Cassandra InputFormat configuration
#
titanmr.ioformat.conf.storage.backend=cassandrathrift
titanmr.ioformat.conf.storage.hostname=WORKER1,WORKER2,WORKER3
titanmr.ioformat.conf.storage.port=9160
titanmr.ioformat.conf.storage.keyspace=titan
titanmr.ioformat.cf-name=edgestore
#
# Apache Cassandra InputFormat configuration
#
cassandra.input.partitioner.class=org.apache.cassandra.dht.Murmur3Partitioner
cassandra.input.keyspace=titan
cassandra.input.predicate=0c00020b0001000000000b000200000000020003000800047fffffff0000
cassandra.input.columnfamily=edgestore
cassandra.range.batch.size=2147483647
#
# SparkGraphComputer Configuration
#
spark.master=spark://COORDINATOR:7077
spark.serializer=org.apache.spark.serializer.KryoSerializer答案
这导致了以下答案:
这个设置正确吗?
好像是的。至少它适用于这种设置。
土卫六是否也应该安装在3个星火从节点和/或星火主节点上?
因为它不是必需的,所以我不会这样做,因为我更喜欢将Spark和Titan服务器分开,用户可以访问。
您是否会使用另一种设置?
我会很高兴听到其他人谁有不同的设置。
星火奴隶是否只读取来自分析DC的数据,甚至从同一节点上的Cassandra读取数据?
由于Cassandra节点(来自分析DC)是显式配置的,Spark从节点中不应该能够从完全不同的节点中提取数据。但对于第二部分,我仍然不太清楚。也许其他人能在这里提供更多的洞察力?
https://stackoverflow.com/questions/40105047
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号