
熊猫切片多指标数据
熊猫切片多指标数据
提问于 2016-10-13 15:08:27
我想切一个多索引的熊猫数据
下面是获取我的测试数据的代码:
import pandas as pd
testdf = {
'Name': {
0: 'H', 1: 'H', 2: 'H', 3: 'H', 4: 'H'}, 'Division': {
0: 'C', 1: 'C', 2: 'C', 3: 'C', 4: 'C'}, 'EmployeeId': {
0: 14, 1: 14, 2: 14, 3: 14, 4: 14}, 'Amt1': {
0: 124.39, 1: 186.78, 2: 127.94, 3: 258.35000000000002, 4: 284.77999999999997}, 'Amt2': {
0: 30.0, 1: 30.0, 2: 30.0, 3: 30.0, 4: 60.0}, 'Employer': {
0: 'Z', 1: 'Z', 2: 'Z', 3: 'Z', 4: 'Z'}, 'PersonId': {
0: 14, 1: 14, 2: 14, 3: 14, 4: 15}, 'Provider': {
0: 'A', 1: 'A', 2: 'A', 3: 'A', 4: 'B'}, 'Year': {
0: 2012, 1: 2012, 2: 2013, 3: 2013, 4: 2012}}
testdf = pd.DataFrame(testdf)
testdf
grouper_keys = [
'Employer',
'Year',
'Division',
'Name',
'EmployeeId',
'PersonId']
testdf2 = pd.pivot_table(data=testdf,
values='Amt1',
index=grouper_keys,
columns='Provider',
fill_value=None,
margins=False,
dropna=True,
aggfunc=('sum', 'count'),
)
print(testdf2)给予:
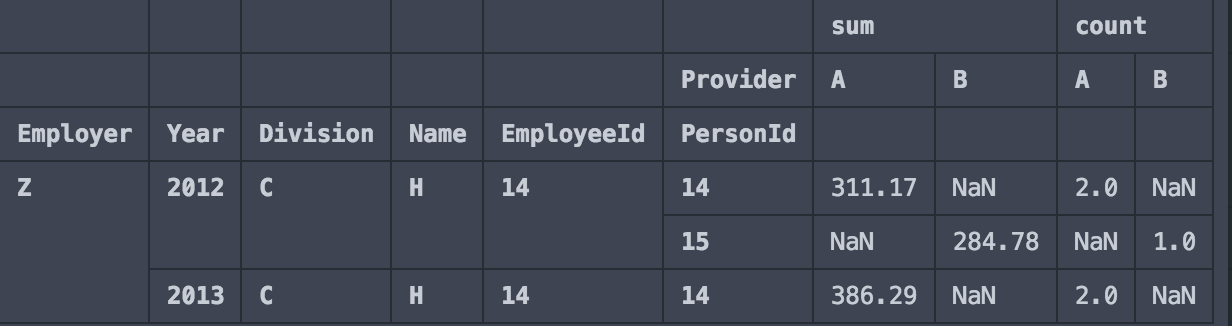
现在,我只能获得用于A或B的
testdf2.loc[:, slice(None, ('sum', 'A'))]这给
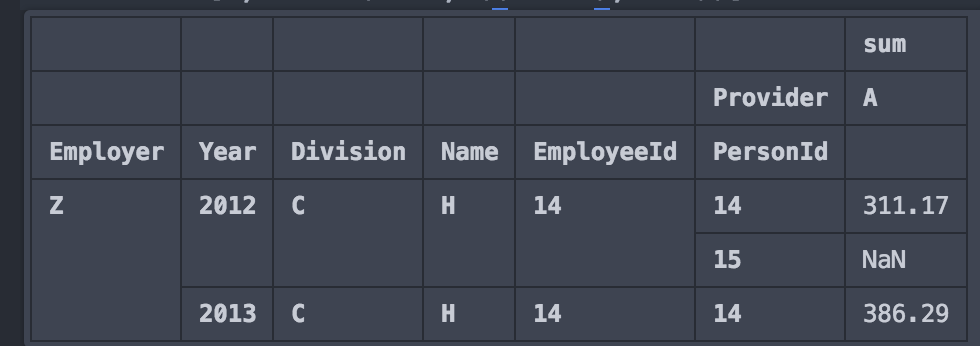
我怎样才能让( sum )和 count (只为A或B )
回答 2
Stack Overflow用户
回答已采纳
发布于 2016-10-13 15:13:46
您可以使用:
idx = pd.IndexSlice
df = testdf2.loc[:, idx[['sum', 'count'], 'A']]
print (df)
sum count
Provider A A
Employer Year Division Name EmployeeId PersonId
Z 2012 C H 14 14 311.17 2.0
15 NaN NaN
2013 C H 14 14 386.29 2.0另一种解决办法是:
df = testdf2.loc[:, (slice('sum','count'), ['A'])]
print (df)
sum count
Provider A A
Employer Year Division Name EmployeeId PersonId
Z 2012 C H 14 14 311.17 2.0
15 NaN NaN
2013 C H 14 14 386.29 2.0Stack Overflow用户
发布于 2016-10-13 15:17:13
横截面使用xs
testdf2.xs('A', axis=1, level=1)
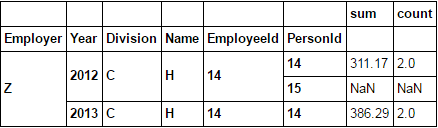
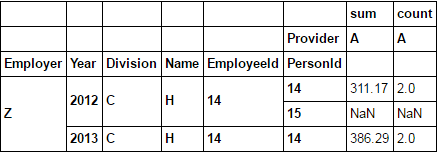
或者用drop_level=False保持列的水平
testdf2.xs('A', axis=1, level=1, drop_level=False)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/40024721
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号