
神经网络的异常结果
我写了一个简单的前馈人工神经网络来识别符号。
我在一个5x5像素网格中有一组6个可能的符号。
这些是{X, +, -, \, /, |}
例如,X将是:
X = [1,0,0,0,1,
0,1,0,1,0,
0,0,1,0,0,
0,1,0,1,0,
1,0,0,0,1]灰色噪声区域的值可以在0到1之间。
我的神经网络由25个输入神经元( 5x5栅格)、6个有偏见的隐神经元和6个输出神经元组成。
每个输出神经元映射到一个符号。0到1之间的输出决定它识别哪个符号,即选择符号作为输出节点的最大值。
也就是说,如果输出是{X : 0.9, + : 0.2, - : 0.1, \ : 0.15, / : 0.15, | : 0.2},那么可识别的符号将是X。
看来效果很好。然后我做了以下实验:
我得到了测试输入(上面的6个符号),并创建了一个噪声函数addNoise(n),其中n是随机添加到输入中的噪声的百分比。
对于0和1之间的每个噪声值,我运行了测试2000时间(每次噪声随机变化)。在X上执行此操作时,我得到了下面的图表。
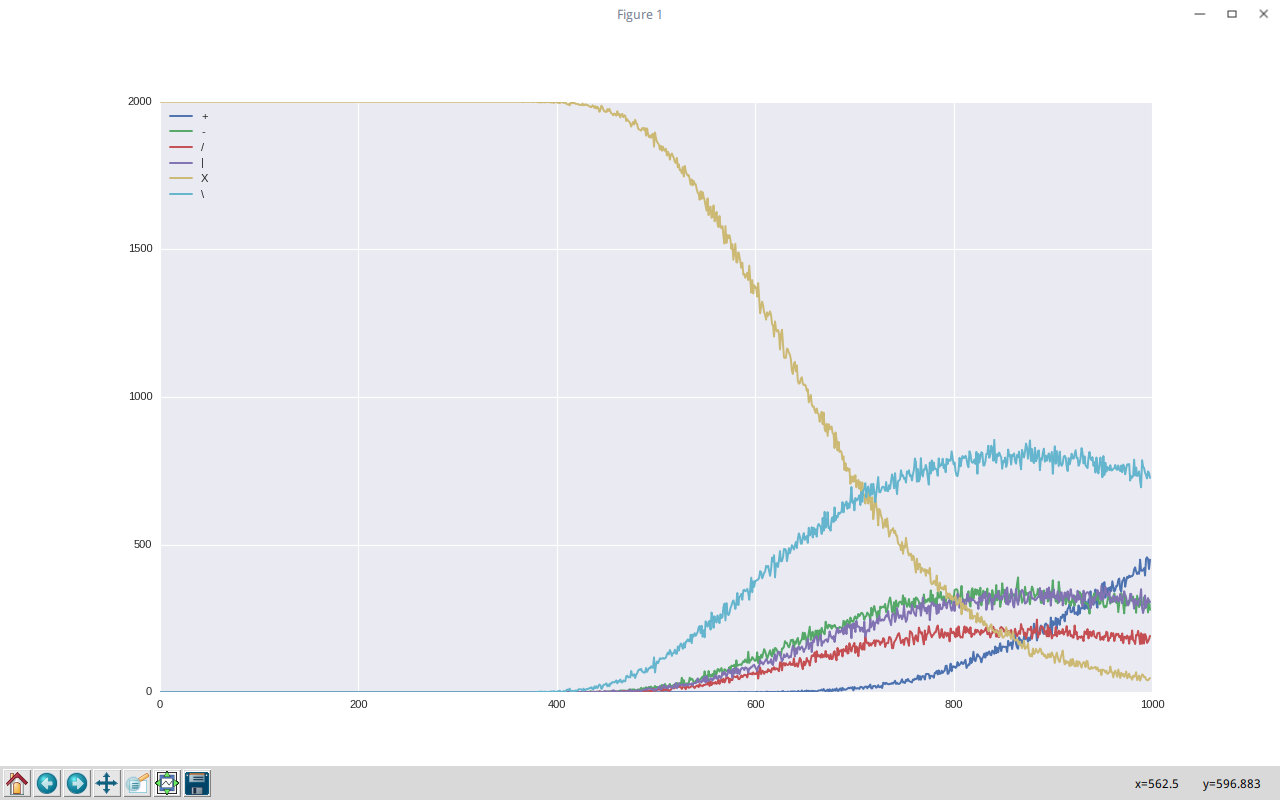
您可能需要打开另一个页面上的图像才能看到完整的大小。
正如您所看到的,在我向X测试输入注入大约40% (x轴400)噪声后,它开始预测其他符号。
随着70%噪声加入到X中,网络预测X和\的几率是相等的。
总之,我的问题是:
对于\和/,图形上的线条不应该几乎完全对齐,因为它们与X符号是完全相同的吗?
为了澄清,在70%噪声之后,网络同样将X和\混为一谈。
然而,经过~88%噪声后,网络同样混合了X和/。
为什么我的网络会产生这样的结果?
回答 1
Stack Overflow用户
发布于 2016-10-12 21:11:46
您假设网络在培训期间正在学习字符X的X表示。可能它学到的内部表示严重偏向于/,并混合了一些\。也就是说,如果输入有强/组件和一些\组件--那么就预测X。这些信息足以区分X和其他字符(干净时)。训练神经网络是基于损失函数的,如果这种表示已经满足我们的要求,那么网络就不需要学习更健壮的表示。
在这种假设情况下,与/相比,注入少量的噪声很容易掩盖/分量,这就需要注入大量的噪声。
https://stackoverflow.com/questions/40007219
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号