
在Pandas (Python)中争论数据帧
我在csv文件中有以下数据:
from StringIO import StringIO
import pandas as pd
the_data = """
ABC,2016-6-9 0:00,95,{'//Purple': [115L], '//Yellow': [403L], '//Blue': [16L], '//White-XYZ': [0L]}
ABC,2016-6-10 0:00,0,{'//Purple': [219L], '//Yellow': [381L], '//Blue': [90L], '//White-XYZ': [0L]}
ABC,2016-6-11 0:00,0,{'//Purple': [817L], '//Yellow': [21L], '//Blue': [31L], '//White-XYZ': [0L]}
ABC,2016-6-12 0:00,0,{'//Purple': [80L], '//Yellow': [2011L], '//Blue': [8888L], '//White-XYZ': [0L]}
ABC,2016-6-13 0:00,0,{'//Purple': [32L], '//Yellow': [15L], '//Blue': [4L], '//White-XYZ': [0L]}
DEF,2016-6-16 0:00,0,{'//Purple': [32L], '//Black': [15L], '//Pink': [4L], '//NPO-Green': [3L]}
DEF,2016-6-17 0:00,0,{'//Purple': [32L], '//Black': [15L], '//Pink': [4L], '//NPO-Green': [0L]}
DEF,2016-6-18 0:00,0,{'//Purple': [32L], '//Black': [15L], '//Pink': [4L], '//NPO-Green': [7L]}
DEF,2016-6-19 0:00,0,{'//Purple': [32L], '//Black': [15L], '//Pink': [4L], '//NPO-Green': [14L]}
DEF,2016-6-20 0:00,0,{'//Purple': [32L], '//Black': [15L], '//Pink': [4L], '//NPO-Green': [21L]}
"""我将数据读入Pandas数据框架,如下所示:
df = pd.read_csv(StringIO(the_data), sep=',', header=None)“公司”和“日期”字段永远不会更改。
然而,花括号内的“键”(例如"//PurpleCar"、"//YellowCar"、"//BlueCar"、"//WhiteCar"、"//BlackCar"、"//BlackCar"和"NPO-GreenCar")是而不是静态。他们可以(也愿意)经常改变。
(注意:我拥有的另一个脚本输出一个字典并“创建”这个文本文件,这就是这个数据结构)
我希望数据框架如下图所示,以便我可以使用Matplotlib创建可视化:
Company Date Purple Yellow Blue White-XYZ Black Pink NPO-Green
0 ABC 2016-6-9 115 403 16 0 0 0 0
1 ABC 2016-6-10 219 381 90 0 0 0 0
2 ABC 2016-6-11 817 21 31 0 0 0 0
3 ABC 2016-6-12 80 2011 8888 0 0 0 0
4 ABC 2016-6-13 32 15 4 0 0 0 0
5 DEF 2016-6-16 32 0 0 0 15 4 3
6 DEF 2016-6-17 32 0 0 0 15 4 0
7 DEF 2016-6-18 32 0 0 0 15 4 7
8 DEF 2016-6-19 32 0 0 0 15 4 14
9 DEF 2016-6-20 32 0 0 0 15 4 21我面临的问题是:
( a)将“键”值移动到列标题
b)允许“键”值是动态的(同样,它们可以并且将发生变化)
( c)移除方括号('['和']')
( d)删除双斜杠('//')
( e)删除数值后面的"L“
上面的'c‘、'd’和'e‘点可以用以下问题(相关问题)来处理:
“a”和“b”是我一直在努力解决的问题。
有人能找到解决这些问题的方法吗?
谢谢!
* UPDATE *
最初公布的数据有一个小错误。以下是数据:
the_data = """
ABC,2016-6-9 0:00,95,"{'//Purple': [115L], '//Yellow': [403L], '//Blue': [16L], '//White-XYZ': [0L]}"
ABC,2016-6-10 0:00,0,"{'//Purple': [219L], '//Yellow': [381L], '//Blue': [90L], '//White-XYZ': [0L]}"
ABC,2016-6-11 0:00,0,"{'//Purple': [817L], '//Yellow': [21L], '//Blue': [31L], '//White-XYZ': [0L]}"
ABC,2016-6-12 0:00,0,"{'//Purple': [80L], '//Yellow': [2011L], '//Blue': [8888L], '//White-XYZ': [0L]}"
ABC,2016-6-13 0:00,0,"{'//Purple': [32L], '//Yellow': [15L], '//Blue': [4L], '//White-XYZ': [0L]}"
DEF,2016-6-16 0:00,0,"{'//Purple': [32L], '//Black': [15L], '//Pink': [4L], '//NPO-Green': [3L]}"
DEF,2016-6-17 0:00,0,"{'//Purple': [32L], '//Black': [15L], '//Pink': [4L], '//NPO-Green': [0L]}"
DEF,2016-6-18 0:00,0,"{'//Purple': [32L], '//Black': [15L], '//Pink': [4L], '//NPO-Green': [7L]}"
DEF,2016-6-19 0:00,0,"{'//Purple': [32L], '//Black': [15L], '//Pink': [4L], '//NPO-Green': [14L]}"
DEF,2016-6-20 0:00,0,"{'//Purple': [32L], '//Black': [15L], '//Pink': [4L], '//NPO-Green': [21L]}"
"""这些数据与原始数据之间的区别是,在开始大括号( (") )之前的撇号(("))和在结束大括号("}")之后的撇号。
回答 2
Stack Overflow用户
发布于 2016-10-08 20:25:03
我真的不认为这只熊猫能为你做什么。您的数据非常枯燥,在我看来,最好使用正则表达式来处理。这是我的解决方案:
import re
static_cols = []
dynamic_cols = []
for line in the_data.splitlines():
if line == '':
continue
# deal with static columns
x = line.split(',')
company, date, other = x[0:3]
keys = ['Company', 'Date', 'Other']
values = [company, date, other]
d = {i: j for i, j in zip(keys, values)}
static_cols.append(d)
# deal with dynamic columns
keys = re.findall(r'(?<=//)[^\']*', line)
values = re.findall(r'\d+(?=L)', line)
d = {i: j for i, j in zip(keys, values)}
dynamic_cols.append(d)
df1 = pd.DataFrame(static_cols)
df2 = pd.DataFrame(dynamic_cols)
df = pd.concat([df1, df2], axis=1)以及产出:
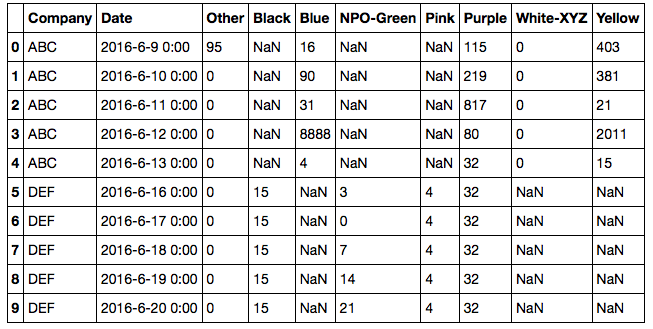
另外,在我不知道该如何处理的日期之后,您的数据还有一个额外的列,所以我称之为“Other”。它没有包含在您的输出中,所以您也可以轻松地删除它。
Stack Overflow用户
发布于 2016-10-08 22:54:19
考虑使用ast.literal_eval()将字典列值转换为Python字典,然后将它们转换为单个数据格式,以便与原始数据cast进行最终合并:
from io import StringIO
import pandas as pd
import ast
...
df = pd.read_csv(StringIO(the_data), header=None,
names=['Company', 'Date', 'Value', 'Dicts'])
dfList = []
for i in df['Dicts'].tolist():
result = ast.literal_eval(i.replace('L]', ']'))
result = {k.replace('//',''):v for k,v in result.items()}
temp = pd.DataFrame(result)
dfList.append(temp)
dictdf = pd.concat(dfList).reset_index(drop=True)
df = pd.merge(df, dictdf, left_index=True, right_index=True).drop(['Dicts'], axis=1)
print(df)
# Company Date Value Black Blue NPO-Green Pink Purple White-XYZ Yellow
# 0 ABC 2016-6-9 0:00 95 NaN 16.0 NaN NaN 115 0.0 403.0
# 1 ABC 2016-6-10 0:00 0 NaN 90.0 NaN NaN 219 0.0 381.0
# 2 ABC 2016-6-11 0:00 0 NaN 31.0 NaN NaN 817 0.0 21.0
# 3 ABC 2016-6-12 0:00 0 NaN 8888.0 NaN NaN 80 0.0 2011.0
# 4 ABC 2016-6-13 0:00 0 NaN 4.0 NaN NaN 32 0.0 15.0
# 5 DEF 2016-6-16 0:00 0 15.0 NaN 3.0 4.0 32 NaN NaN
# 6 DEF 2016-6-17 0:00 0 15.0 NaN 0.0 4.0 32 NaN NaN
# 7 DEF 2016-6-18 0:00 0 15.0 NaN 7.0 4.0 32 NaN NaN
# 8 DEF 2016-6-19 0:00 0 15.0 NaN 14.0 4.0 32 NaN NaN
# 9 DEF 2016-6-20 0:00 0 15.0 NaN 21.0 4.0 32 NaN NaNhttps://stackoverflow.com/questions/39935744
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号