
Google NL定位实体识别中的问题
我一直在玩Google自然语言API,特别是使用位置识别从HN的“谁在雇用”页面中提取位置。如果我传递这样的短信
Blockai _ San Francisco,CA _ CV/ML和前端工程师- https://blockai.com“
(来自https://news.ycombinator.com/item?id=12631335)
然后NL API返回以下实体:
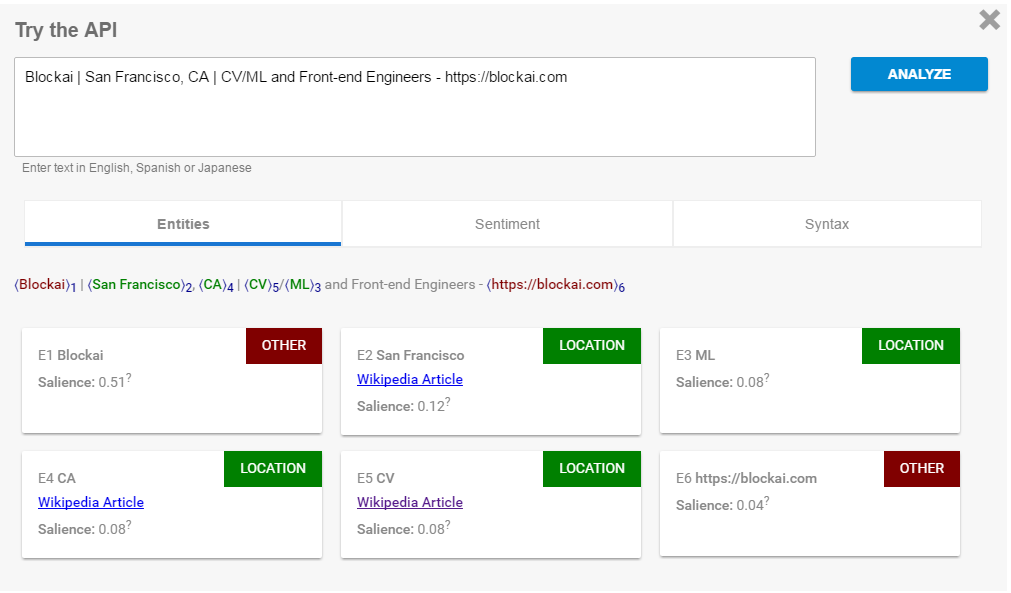
问题是"ML“和"CV”被认为是地点,但它们实际上分别代表“机器学习”和“计算机视觉”。我猜算法的结论是CV/ML是位置,因为它们靠近文本中的其他位置(旧金山,CA)。
我想知道如何在API的输出中识别这样的“假”位置?我认为使用“显著”参数可能会有帮助,但我不确定什么经验法则是合适的。我甚至发现API的显着性值有时大于1,尽管docs说这些值“在0,1.0范围内”,F.E:
{
"name":"San Francisco",
"type":"LOCATION",
"metadata":{
"wikipedia_url":"http://en.wikipedia.org/wiki/San_Francisco"
},
"salience":1.4515763148665428,
"mentions":[ ]},
任何帮助都是非常感谢的!
回答 1
Stack Overflow用户
发布于 2016-12-30 09:12:51
有时候,对于底层算法来说,消除实体的歧义是非常棘手的,尤其是。当没有足够的上下文时。凸性对此没有帮助,因为显着性说明了一个实体是多么的中心,而不管它的类型如何。在这种情况下,您可以使用提供的元数据(例如wikipedia url)进一步评估实体是否确实是一个位置。
https://stackoverflow.com/questions/39908591
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号