
C# Tessnet2 OCR不返回正确的值
C# Tessnet2 OCR不返回正确的值
提问于 2016-09-28 18:18:53
好吧,今天我花了最好的时间让ocr正常工作,它不再崩溃,但是当我给它一个包含文本的文件,而不是仅仅是数字,很多奇怪的文本就会被抽出来……
源代码:
using System;
using System.Collections.Generic;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using tessnet2;
namespace OCRTest
{
class Program
{
static void Main(string[] args)
{
try
{
var image = new Bitmap(@"C:\Users\Ryan\Documents\visual studio 2015\Projects\OCRTest\testimage.jpg");
var ocr = new Tesseract();
ocr.Init(@"C:\Users\Ryan\Documents\visual studio 2015\Projects\OCRTest\tessdata", "eng", true);
var result = ocr.DoOCR(image, Rectangle.Empty);
foreach (Word word in result)
{
Console.WriteLine("{0} : {1}", word.Confidence, word.Text);
}
}
catch (Exception exception)
{
Console.WriteLine(exception);
}
Console.ReadLine();
}
}
}就像我说的,我正在使用tessnet2和。
当我输入这个图像时:

我从节目中得到了这样的回应:
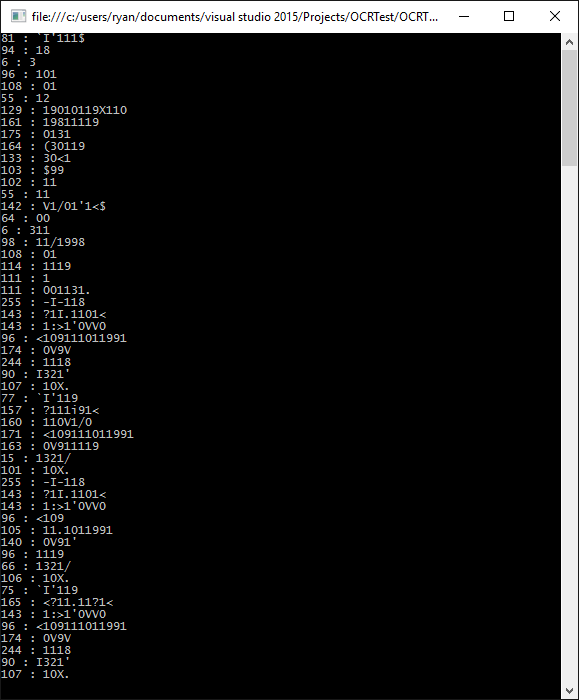
谢谢您的任何帮助或链接,您可能有进一步的教程-我遵循这教程到目前为止。瑞安
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-09-28 18:36:23
修正了这个问题--我做了一个愚蠢的事情,把ocr.Init()的最后一个参数设置为true而不是false.
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/39754903
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号