
使用Mac上文档中的内容对PDF进行批重命名
我有7000 pdf文档在文件夹"ffl“,他们都已经通过ocr程序,以便内容可以复制和粘贴。
每个文档都包含文本"license -__----*****“”号码是15位长有破折号,第10项是一个字母。
需要批处理才能根据文档中的许可证号重命名所有文件。
有我可以运行的脚本来完成这个任务吗?已经搜寻了大约一周了。每件事都在谈论从finder重命名的新方法。没有任何关于从文档内容中重命名的内容。对终点站来说很新鲜。
我看到了将mv重命名为“旧位置”“新位置”的基本命令。
mv /home/user/my_static /home/user/static
现在,我复制数字并粘贴为文件名。需要一个更快的方法。
请并感谢您的任何建议。
回答 3
Stack Overflow用户
发布于 2016-09-22 23:06:17
请先安装pip:
sudo easy_install pip或
brew install python其次,安装pdfminer:
pip install pdfminer通过使用pdfminer和Python的标准库,我创建了一个特定于您的问题的脚本:
rename.py
import commands
import re
import glob, os
os.chdir(".") # In this directory
for file in glob.glob("*.pdf"): # For all files with extension .pdf
pdf_text = commands.getstatusoutput('pdf2txt.py ' + file)[1] # Get text content of the pdf file
result = re.search('[0-9]-[0-9][0-9]-[0-9][0-9][0-9]-[0-9][0-9]-[0-9][A-Z]-[0-9][0-9][0-9][0-9][0-9]', pdf_text) # Search using a regex specific to your solution and find the license number
if result: # If license number has been found
command = 'mv ' + file + ' ' + result.group(0) + '.pdf'
commands.getstatusoutput(command) # Rename file to LICENSE_NUMBER.pdf
print command + ' :: Command executed.' # Show what command has been executed只需输入python rename.py即可执行它。
这个Python脚本将在目录(与其本身相同的目录)中搜索扩展名为.pdf的文件。
然后,它将根据我为您编写的正则表达式搜索每个文件的许可证号。
最后,如果有结果,它将将文件名更改为LICENSE_NUMBER.pdf
在OP的评论中添加:
如果其他一些PDF文档的格式略有不同,并且此脚本不适用于它们,只需使用以下方法查看文本内容:
commands.getstatusoutput('pdf2txt.py ' + file)对于您的示例文件,它是:
...ct ATI- \nCorrespondence To\n\nLicense\nNumber\n\n9-91-053-01-4L-04292\n\nA IF - Chief. FF...因此,我创建了一个regex来查找子字符串\n\nLicense\nNumber\n\n9-91-053-01-4L-04292\n\nA并从中获取许可号。也许您可以通过调查更多的示例来为PDF文档创建一个更宽容/更通用的正则表达式。
Stack Overflow用户
发布于 2016-09-23 08:50:59
最新答案
好吧,我想我们可以做得更好,我更了解数字的格式.
#!/bin/bash
# Don't barf if no files, or if upper or lower case names
shopt -s nullglob nocaseglob
for f in *.pdf; do
lic=$(pdfgrep "[0-9]-[0-9][0-9]-[0-9][0-9][0-9]-[0-9][0-9]-[0-9][A-Z]-[0-9][0-9][0-9][0-9][0-9]" "$f" | grep -oE "[0-9-]+[A-Z][0-9-]+")
# Check licence is at least 15 characters, else do nothing
if [ ${#lic} -gt 15 ]; then
echo mv "$f" "${lic}.pdf"
fi
done如果要花费很长时间,您还可以使用homebrew安装GNU并行,这样就可以并行地完成所有这些任务,并使工作完成得更快。因此,您可以用以下方式安装:
brew install parallel然后将脚本更改为只执行一个文件,如下所示:
#!/bin/bash
if [ $# -ne 1 ]; then
echo Usage: Renamer file
exit 1
fi
f="$1"
lic=$(pdfgrep "[0-9]-[0-9][0-9]-[0-9][0-9][0-9]-[0-9][0-9]-[0-9][A-Z]-[0-9][0-9][0-9][0-9][0-9]" "$f" | grep -oE "[0-9-]+[A-Z][0-9-]+")
# Check licence is at least 15 characters, else do nothing
if [ ${#lic} -gt 15 ]; then
echo mv "$f" "${lic}.pdf"
fi然后你就可以把它们都搞定:
parallel ./Renamer ::: *.pdf备选案文1
您可以使用pdfgrep提取许可证号码,您可以使用homebrew安装许可证号码。您需要到自制的乳酪,从那里复制一行(我不想放在这里,以防它过时),并将其粘贴到终端并运行它。然后,您可以通过以下方式安装pdfgrep:
brew install pdfgrep或者,如果您喜欢这样的事情,可以下载并自己构建pdfgrep!下载。
然后,您可以通过以下方式从PDF文件中提取许可证:
pdfgrep -i "License Number" SomeFile.pdf | grep -oE "[0-9-]+[A-Z][0-9-]+"并将其放入一个变量中:
lic=$(pdfgrep -i "License Number" SomeFile.pdf | grep -oE "[0-9-]+[A-Z][0-9-]+")因此,如果目录中有7,000个PDF文件,则需要转到该目录,并将以下内容保存为一个名为NameByLicence的脚本
#!/bin/bash
# Don't barf if no files, or if upper or lower case names
shopt -s nullglob nocaseglob
for f in *.pdf; do
lic=$(pdfgrep -i "License Number" "$f" | grep -oE "[0-9-]+[A-Z][0-9-]+")
# Check licence is at least 15 characters, else do nothing
if [ ${#lic} -gt 15 ]; then
echo mv "$f" "${lic}.pdf"
fi
done保存脚本后,使用以下命令使其可执行(只需一次):
chmod +x NameByLicence然后您可以使用以下方法运行:
./NameByLicence请先备份,然后对几个虚拟文件进行测试
如果它看起来是正确的,删除单词echo,它实际上会进行名称更改--此时它只是告诉您它将做什么,而不是做任何事情。
选项2
如果您不想使用homebrew和pdfgrep,您可以使用本机OSX工具来完成,但这有点困难。基本上,您可以创建一个自动工作流程,将PDF中的文本提取为临时文本文档,然后将其从UTF-16转换为ASCII和grep。如果这对你有意义的话,下面是几个步骤:
创建一个如下所示的Automator工作流:
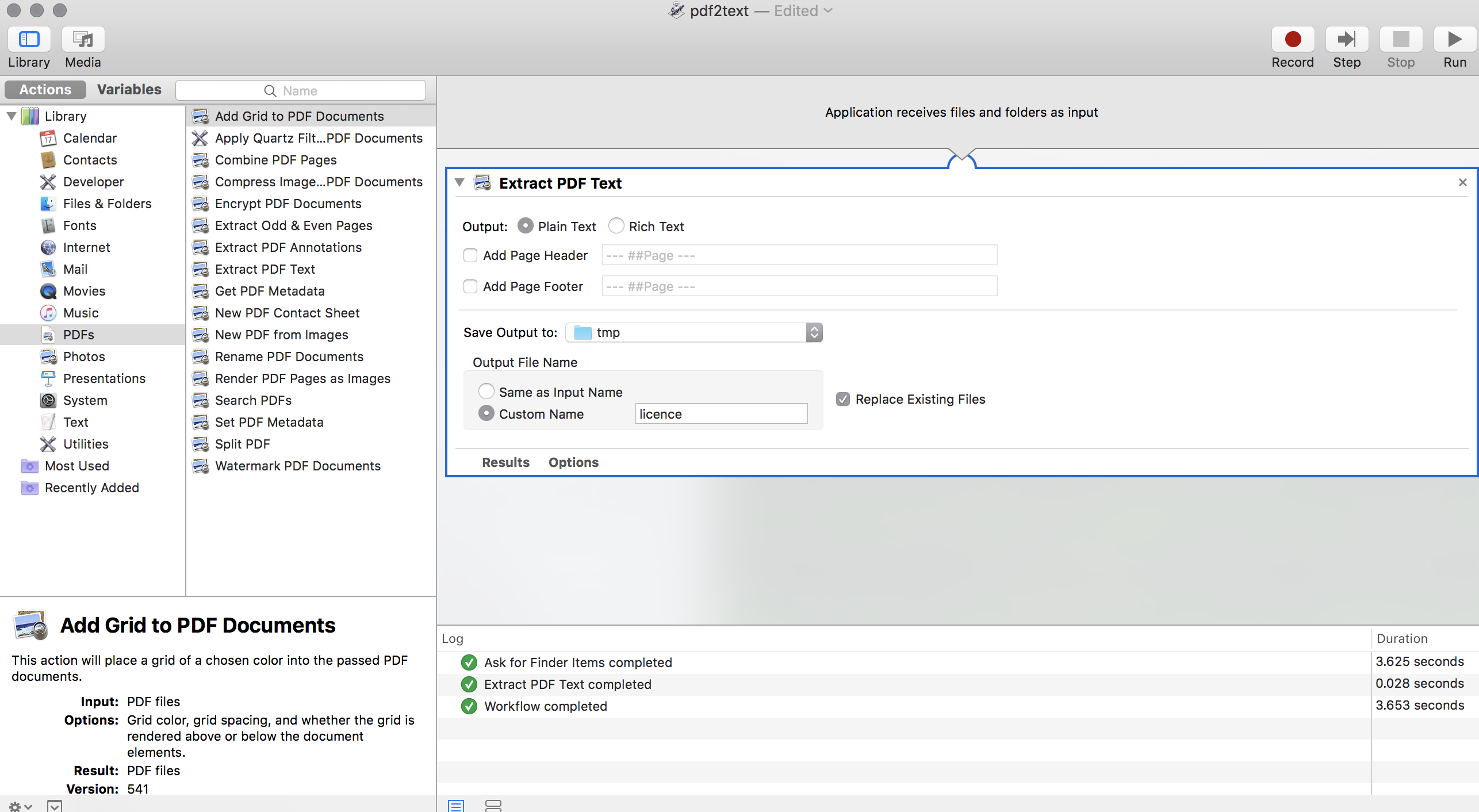
通过使用/tmp并键入/tmp,可以在“将输出保存到”字段中获取/tmp。选中“替换现有文件”框,以便当上一个文件中的许可存在时,它仍然适用于您的第二个。
将其保存为“作为应用程序”,称为pdf2text。现在您可以运行以下代码而不是pdfgrep
./pdf2text.app/Contents/MacOS/"Application Stub" SomeFile.pdf并将文本提取到/tmp/licence.txt中。但是您还没有完成,因为这是UTF-16,所以,要在文件中搜索,您需要:
iconv -c -f UTF-16 -t ASCII /tmp/licence.txt | grep -oE "[0-9A-Z-]{17,}"
9-91-053-01-4L-04292所以,现在您需要将它放在上面的小for脚本中的bash循环中。
Stack Overflow用户
发布于 2017-07-07 19:22:02
我也遇到了类似的问题,我想用从pdf文件中提取的内容重命名一堆pdf文件(在这种情况下是日期)。起初,我只想用pdfgrep进行bash,但是brew的安装在我身上爆炸了(似乎公式没有更新)。
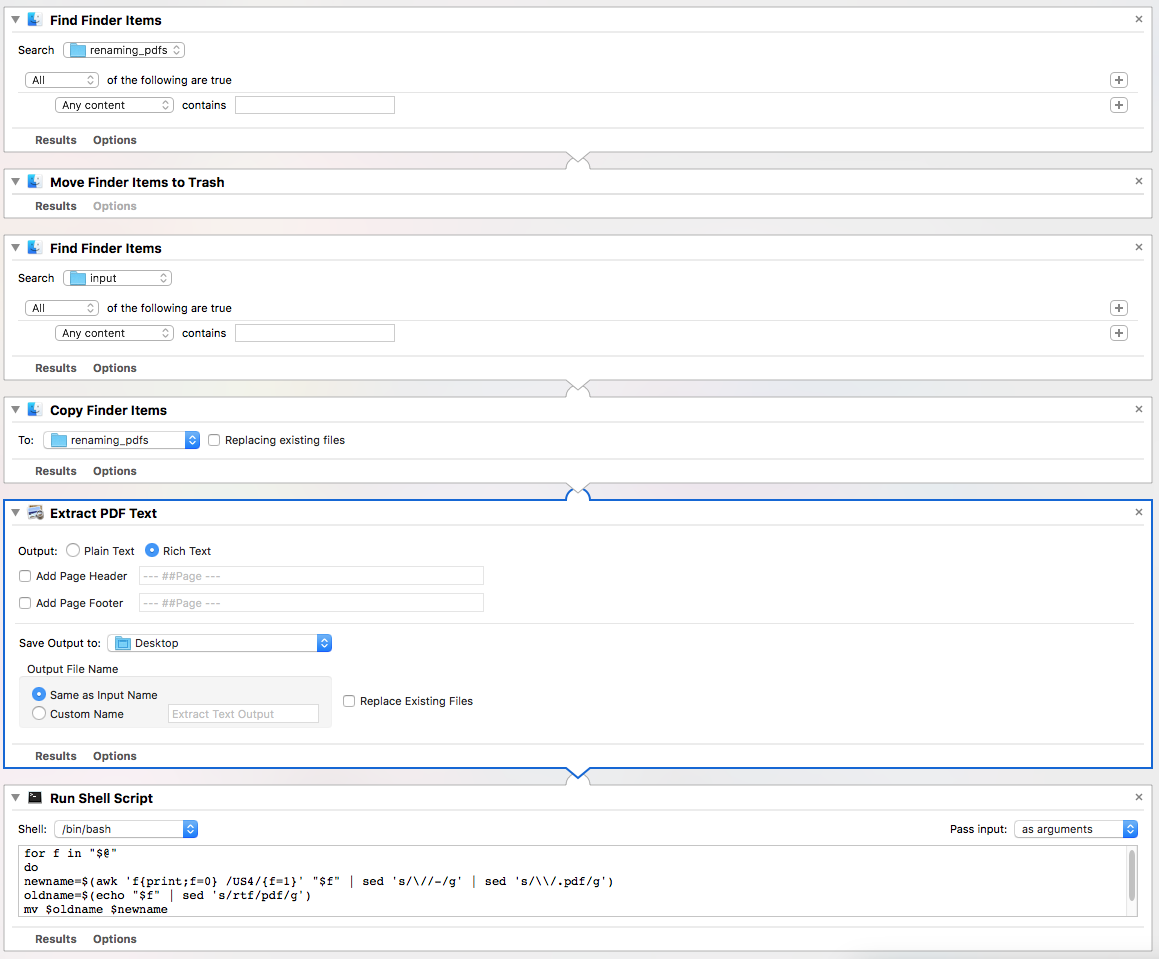
对我来说起作用的是Automator将pdf内容提取为文本,然后是一个快速而肮脏的脚本来提取文本并重命名。见所附的自动程序操作屏幕截图:
- 第一部分清理临时目录(在我的例子中,将pdfs复制到"renaming_pdfs“中)。
- 将文本提取到rtf中
- 脚本获取要将文件重命名为的文本(在本例中,行的内容跟随"US4")并重命名文件
https://stackoverflow.com/questions/39648806
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号