
从重复实验中估计二项成功概率(matlab中)
假设我有一个成功概率为p的二项式过程,我用N=4试验做了一个实验,并取得了一些成功(0-4)。现在,假设我重复这个实验10,000次(每次实验4次),以获得成功次数的分布,如下所示:
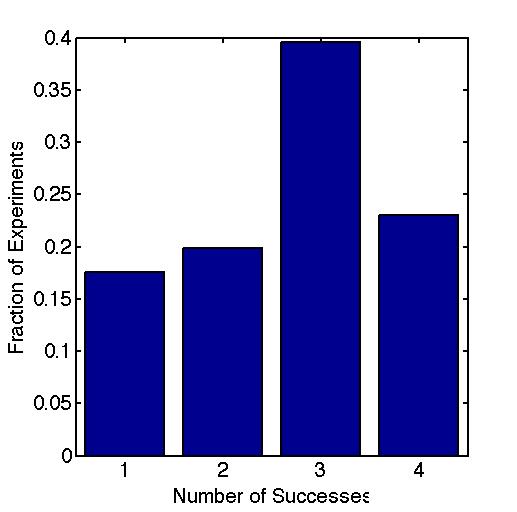
注意,由于实验的方式,我无法记录0成功的实验数据,尽管这无疑是在某种频率上发生的。这就是为什么在图上没有0条的原因。
我如何拟合这些数据来估计概率p(理想情况下,如果我知道实验的次数而不仅仅是比例)的置信区间?我的首选是使用MATLAB,但我愿意使用任何工具来完成这项工作。
更新
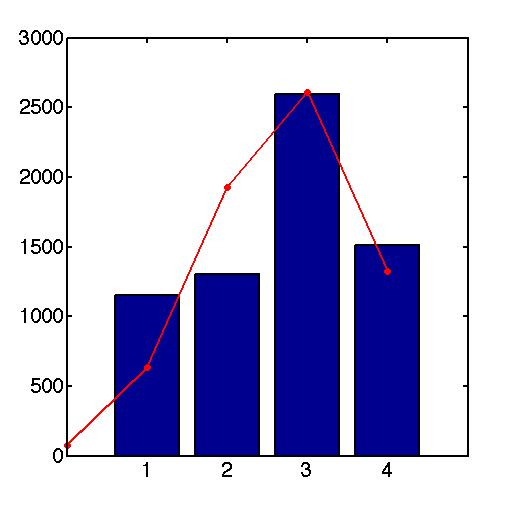
我可以使用mle对数据进行拟合,但拟合效果并不好(见下图)。我认为问题在于缺少的数据(没有观察到0成功的实验)。我是否可以告诉mle只将数据拟合在某个范围内,而忽略其他值?
回答 1
Stack Overflow用户
发布于 2016-09-17 12:51:36
在本例中,我们有一个自定义截断二项分布。Matlab具有fitdist函数,但只接受预定义的分布,不接受累积分布。正如您注意到的,您可以使用任何工具,我用R显示了p参数的估计,但是在Matlab中使用极大似然方法可以估计参数。如果我们用p = 0.3计算4 expriments的二项分布密度函数的值,我们有:
>> den = dbinom(x=0:4, size=4, prob=0.3)
>> print(den)
0.2401, 0.4116, 0.2646, 0.0756, 0.0081由于我们拥有的数据中缺少0值,所以它们的之和=1:
0.4116, 0.2646, 0.0756, 0.0081它们的和小于1 .for,我们用(1-den[1])除以每个
>> print(den[-1] / (1-den[1]))
0.54165022 0.34820371 0.09948677 0.01065930现在它们的总和是1,这样我们就可以得到一个custon分布。
来自fitdistr包的MASS可以满足用户提供的数据密度,因此R中的解决方案是:
library(MASS) # required for fitdistr
#generate 10000 samples from binomial distribution
smpl <- rbinom(n=10000,size=4,prob=.3)
#exclude zeros
smpl <- smpl[-which(smpl==0)]
# custom truncated density
truncated_dbinom <- function(x, prob){
dbinom(x, 4, prob)/(1-dbinom(0, 4, prob));
}
#fit distribution to data
out <- fitdistr(smpl, truncated_dbinom,list(prob=.5),method = "Brent",lower=0,upper=1)
#estimate of p
print(out$estimate)
#standard deviation
print(out$sd)结果:
[1] 0.3092295
[1] 0.01070016https://stackoverflow.com/questions/39539732
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号