
R图重合图
R图重合图
提问于 2016-09-16 16:51:21
我正在建立一个有多种疾病患者的数据库,并试图创建一个图表,显示这些疾病之间的联系。更具体地说,我想获得以下内容:
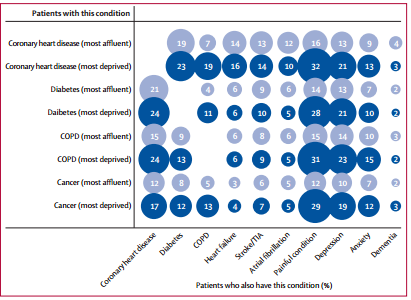
我的数据组织如下:
mal1 mal2 mal3 etc.
0 0 1
1 1 0
0 1 0 etc.我根据需要使用以下代码创建数据:
X <- as.matrix(hdat2)
out <- crossprod(X)
diag(out) <- 0 我创作的情节是:
out<- melt(out)
out$value[which(out$value==0)]<-NA
g <- ggplot(data.frame(out), aes(Var1, Var2)) + geom_point(aes(size = value), colour = "black") + theme_bw() + xlab("") + ylab("")
g + scale_size_continuous(range=c(2,10))+因此我得到了这个情节
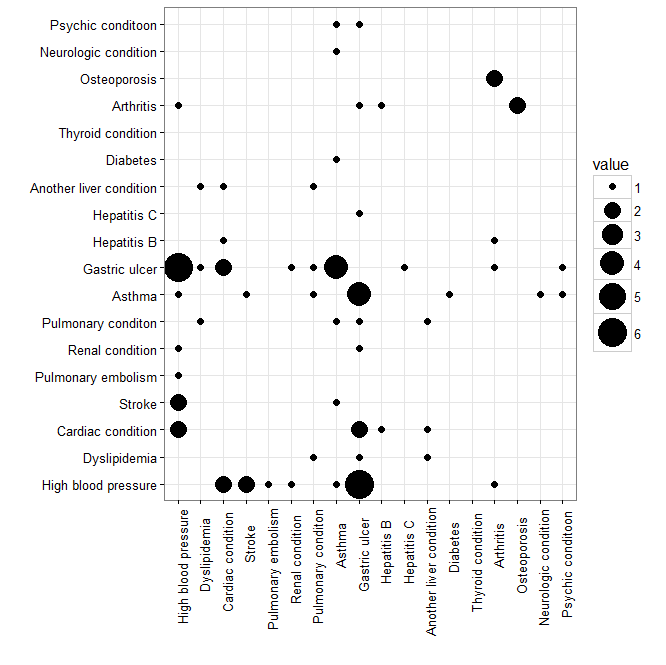
,我想隐藏情节的系统部分,我认为这是误导性的(类似于我如何关联矩阵,我可以隐藏系统的一半)。但是,我不知道该怎么做。
有人能帮忙吗?谢谢
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-09-16 17:33:43
第一,一些可重复的数据:
mat <-
data.frame(
malA = sample(0:1, 100, TRUE, c(0.2,0.8))
, malB = sample(0:1, 100, TRUE, c(0.3,0.7))
, malC = sample(0:1, 100, TRUE, c(0.4,0.6))
, malD = sample(0:1, 100, TRUE, c(0.5,0.5))
)
out <- crossprod(as.matrix(mat))
diag(out) <- 0下面是一个仅限于您对使用dplyr感兴趣的一半的示例
toPlotHalf <-
melt(out) %>%
mutate_each(funs(factor(.))
, starts_with("Var")) %>%
filter(as.numeric(Var1) < as.numeric(Var2))
ggplot(toPlotHalf
, aes(Var1, Var2)) +
geom_point(aes(size = value), colour = "black") +
theme_bw() + xlab("") + ylab("") +
scale_size_continuous(range=c(2,10))
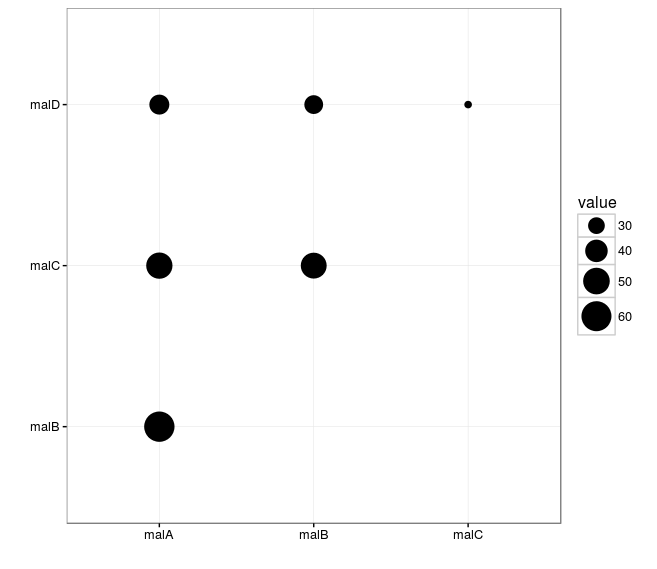
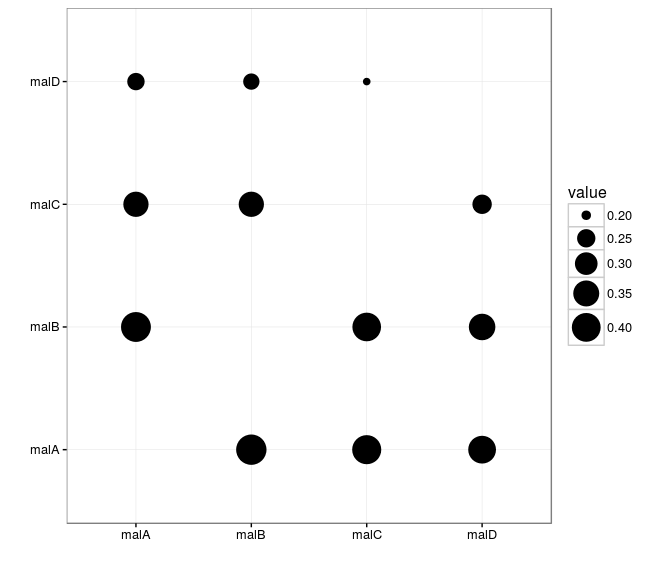
但是,请注意,以这种方式,您的情节将被非常常见的特殊疾病所主导。或者,您也可以显示患有各种疾病的人中有其他疾病的百分比(注意,现在互惠点不一定是相同大小的:
toPlot <-
prop.table(out, 1) %>%
melt() %>%
filter(value > 0)
ggplot(toPlot
, aes(Var1, Var2)) +
geom_point(aes(size = value), colour = "black") +
theme_bw() + xlab("") + ylab("") +
scale_size_continuous(range=c(2,10))
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/39536564
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号