
在需要时不要使用更多的连接
我试图理解Hikari是如何工作的,我读过很多文档,但我有一个用例,它的行为我不理解。
我在Hikari中使用了Slick 3,这是默认配置。我已经有了一个生产应用程序,同时连接了大约1000个用户。我的应用程序使用websockets,当我部署一个新版本时,所有客户端都会重新连接。(我知道这不是处理部署的最佳方法,但我目前还没有集群。)当所有这些用户重新连接时,他们都开始执行查询以获得他们的用户状态(狗堆效应)。当它发生时,斯利克开始抛出许多错误,比如:
java.util.concurrent.RejectedExecutionException: Task slick.backend.DatabaseComponent$DatabaseDef$$anon$2@4dbbd9d1 rejected from java.util.concurrent.ThreadPoolExecutor@a3b8495[Running, pool size = 20, active threads = 20, queued tasks = 1000, completed tasks = 23740]我认为正在发生的情况是,用于挂起的查询的灵活队列已满,因为它不能处理从数据库请求信息的所有客户端。但是,如果我看到Dropwizard提供给我的指标,我会看到以下内容:
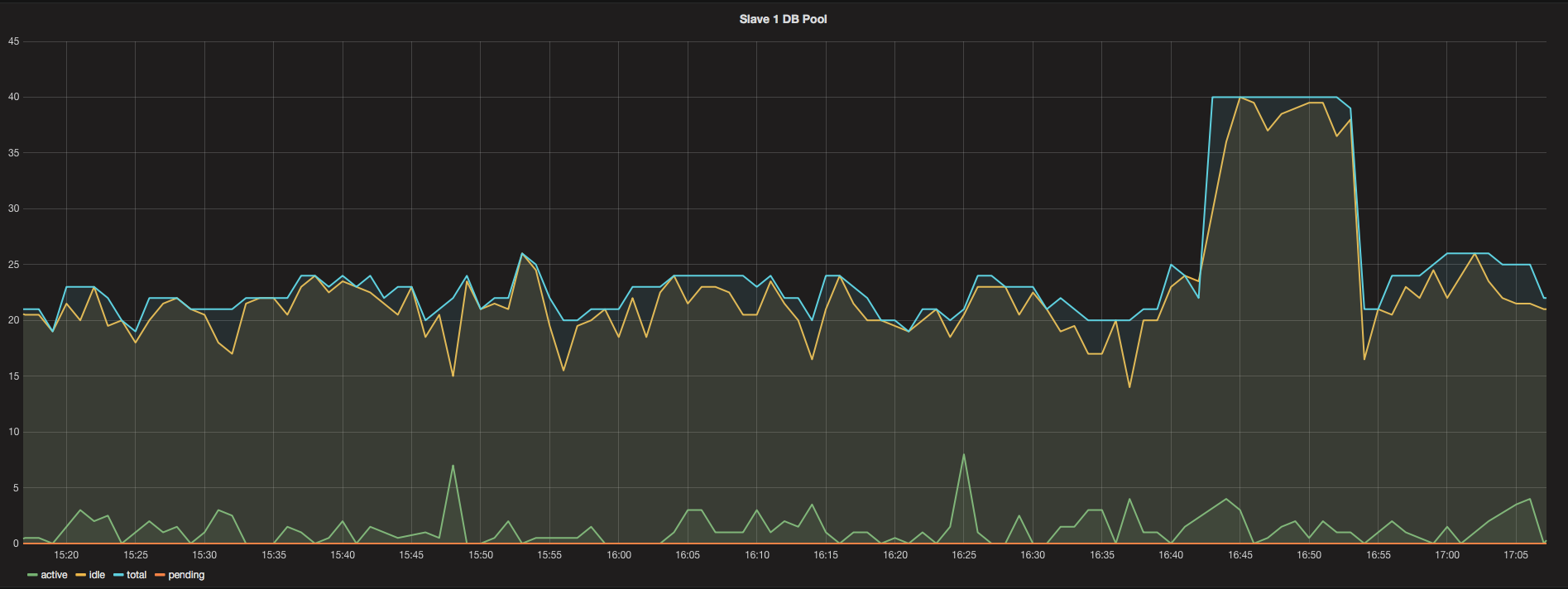
在16:45附近,我们进行了部署。在旧实例终止之前,我们可以看到连接的数量从20条增加到40条。考虑到部署过程是如何完成的,我认为这是正常的。
但是,如果Slick的查询队列由于狗堆效应而变得满,那么如果它有20个可用的连接,为什么不使用超过3-5个连接呢?数据库运行得很好,所以我认为瓶颈就在这里。
对于改进此部署过程,您有什么建议吗?我现在只有1000个用户,但是几周后我会有更多的用户。
回答 1
Stack Overflow用户
发布于 2016-09-18 05:03:19
基于“拒绝”异常,我认为许多光滑操作是并发提交给slick的,这超出了嵌入在slick中的队列的默认大小(1000)。
所以我觉得你应该:
- 增加队列大小(QueueSize)以保存更多未处理的操作。
- 增加slick中的线程数(NumThreads),以同时处理更多的操作。You can get more tips here
https://stackoverflow.com/questions/39532575
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号