
有Pandas列包含列表,如何将唯一的列表元素枢轴到列?
我写了一个网络刮刀,从一个产品表中提取信息,并构建一个数据框架。数据表有一个Description列,该列包含描述产品的逗号分隔的属性字符串。我希望在dataframe中为每个唯一属性创建一个列,并使用属性的子字符串填充该列中的行。下面是示例df。
PRODUCTS DATE DESCRIPTION
Product A 2016-9-12 Steel, Red, High Hardness
Product B 2016-9-11 Blue, Lightweight, Steel
Product C 2016-9-12 Red我认为第一步是将描述分割成一个列表。
In: df2 = df['DESCRIPTION'].str.split(',')
Out:
DESCRIPTION
['Steel', 'Red', 'High Hardness']
['Blue', 'Lightweight', 'Steel']
['Red']我想要的输出如下表所示。列名并不特别重要。
PRODUCTS DATE STEEL_COL RED_COL HIGH HARDNESS_COL BLUE COL LIGHTWEIGHT_COL
Product A 2016-9-12 Steel Red High Hardness
Product B 2016-9-11 Steel Blue Lightweight
Product C 2016-9-12 Red我相信这些列可以使用Pivot来设置,但是我不确定在建立这些列之后用哪种最Pythonic的方式来填充它们。任何帮助都是非常感谢的。
更新
非常感谢你的回答。我选择@MaxU的反应是正确的,因为它看起来稍微灵活一些,但是@piRSquared得到了一个非常相似的结果,甚至可能被认为是Pythonic方法。我测试了这两个版本,并且都做了我需要的事情。谢谢!
回答 5
Stack Overflow用户
发布于 2016-09-12 22:41:19
您可以建立一个稀疏矩阵:
In [27]: df
Out[27]:
PRODUCTS DATE DESCRIPTION
0 Product A 2016-9-12 Steel, Red, High Hardness
1 Product B 2016-9-11 Blue, Lightweight, Steel
2 Product C 2016-9-12 Red
In [28]: (df.set_index(['PRODUCTS','DATE'])
....: .DESCRIPTION.str.split(',\s*', expand=True)
....: .stack()
....: .reset_index()
....: .pivot_table(index=['PRODUCTS','DATE'], columns=0, fill_value=0, aggfunc='size')
....: )
Out[28]:
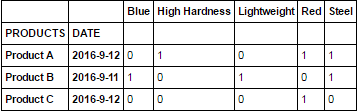
0 Blue High Hardness Lightweight Red Steel
PRODUCTS DATE
Product A 2016-9-12 0 1 0 1 1
Product B 2016-9-11 1 0 1 0 1
Product C 2016-9-12 0 0 0 1 0
In [29]: (df.set_index(['PRODUCTS','DATE'])
....: .DESCRIPTION.str.split(',\s*', expand=True)
....: .stack()
....: .reset_index()
....: .pivot_table(index=['PRODUCTS','DATE'], columns=0, fill_value='', aggfunc='size')
....: )
Out[29]:
0 Blue High Hardness Lightweight Red Steel
PRODUCTS DATE
Product A 2016-9-12 1 1 1
Product B 2016-9-11 1 1 1
Product C 2016-9-12 1Stack Overflow用户
发布于 2016-09-12 23:09:04
使用pd.get_dummies
cols = ['PRODUCTS', 'DATE']
pd.get_dummies(
df.set_index(cols).DESCRIPTION \
.str.split(',\s*', expand=True).stack()
).groupby(level=cols).sum().astype(int)
Stack Overflow用户
发布于 2017-09-07 13:20:36
由@piRSquared和@MaxU发布的答案非常有效。
但是,仅当数据没有任何NaN值时。我处理的数据非常稀少。在应用上述方法后,它大约有100万行,在任何列中删除所有带有NaNs的行时,这些行将减少到大约100行。我花了一天多时间才找到解决办法。共享稍微修改过的代码,以节省其他人的时间。
假设您有上面提到的df DataFrame,
- 首先用其他列中不需要的内容替换所有
NaN,因为稍后必须将其替换回NaN。 df.loc:,cols = df.loc:,cols.fillna("SOME_UNIQ_NAN_REPLACEMENT") 这是需要的,因为groupby删除了所有具有NaN值的行。::/ - 然后,我们用一个小的修改
stack(dropna=False)运行其他答案中建议的内容。默认情况下,dropna=True.df = pd.get_dummies(df.set_index(index_columnscol\ .str.split(",\s*",expand=True).stack(dropna=False),prefix=col)\ .groupby(index_columns,sort=False).sum().astype(int).reset_index() - 然后将
NaN放回df中,以避免更改其他列的数据。 df.replace("SOME_UNIQ_NAN_REPLACEMENT",np.nan,inplace=True)
希望这能为某人省去几个小时的挫折。
https://stackoverflow.com/questions/39459321
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号