
MATLAB:有什么方法可以让两个重塑彼此互相抵消,两个彼此之间保持不变呢?
我有一个3乘3的复矩阵c,所以我必须执行以下操作。c在一般情况下是复杂的,c也可以较大,但它是一个方阵。
c= rand(3,3)
A = bsxfun(@mtimes,permute(reshape(reshape(permute(c(:,1:end~=2)',[2 1]),1,3*2).', 3, []),[3,1,2]),c(:,1))
conj(permute(A,[2 1 3]))然而,时间太长了。哪一部分最费时?
首先,c(:,1:end~=2)'是一个不带第二列的矩阵的复共轭转置。
c = rand(3,3)
c =
0.9791 0.2003 0.9764
0.5933 0.2570 0.4920
0.5811 0.6384 0.9031
c(:,1:end~=2)'
ans =
0.9791 0.5933 0.5811
0.9764 0.4920 0.9031第二,permute(c(:,1:end~=2)',[2 1])是一个使整形按行工作的技巧。
permute(c(:,1:end~=2)',[2 1])
ans =
0.9791 0.9764
0.5933 0.4920
0.5811 0.9031第三,进行reshape和.',使其成为一列:
reshape(permute(c(:,1:end~=2)',[2 1]),1,3*2).'
ans =
0.9791
0.5933
0.5811
0.9764
0.4920
0.9031第四,将列整形为2×3矩阵:
reshape(reshape(permute(c(:,1:end~=2)',[2 1]),1,3*2).', 3, [])
ans =
0.9791 0.9764
0.5933 0.4920
0.5811 0.9031第五,创建一个多维数组,每个层都是列的行向量(只是重新排序,而不是复杂的共轭)。
permute(reshape(reshape(permute(c(:,1:end~=2)',[2 1]),1,3*2).', 3, []),[3,1,2])
ans(:,:,1) =
0.9791 0.5933 0.5811
ans(:,:,2) =
0.9764 0.4920 0.9031第六,使用bsxfun获取每一层的c第一列的外部积。
bsxfun(@mtimes,permute(reshape(reshape(permute(c(:,1:end~=2)',[2 1]),1,3*2).', 3, []),[3,1,2]),c(:,1))
ans(:,:,1) =
0.9587 0.5809 0.5689
0.5809 0.3520 0.3448
0.5689 0.3448 0.3376
ans(:,:,2) =
0.9560 0.4817 0.8843
0.5793 0.2919 0.5359
0.5673 0.2859 0.5248最后一个我不认为可以简化。它的目的是在每一层取矩阵的复共轭:
A = bsxfun(@mtimes,permute(reshape(reshape(permute(c(:,1:end~=2)',[2 1]),1,3*2).', 3, []),[3,1,2]),c(:,1))
A(:,:,1) =
0.9587 0.5809 0.5689
0.5809 0.3520 0.3448
0.5689 0.3448 0.3376
A(:,:,2) =
0.9560 0.4817 0.8843
0.5793 0.2919 0.5359
0.5673 0.2859 0.5248
conj(permute(A,[2 1 3]))
ans(:,:,1) =
0.9587 0.5809 0.5689
0.5809 0.3520 0.3448
0.5689 0.3448 0.3376
ans(:,:,2) =
0.9560 0.5793 0.5673
0.4817 0.2919 0.2859
0.8843 0.5359 0.5248由于巧合,A(:,:,1)是对称的。
回答 2
Stack Overflow用户
发布于 2016-08-26 01:09:54
要直接回答你的问题:
- 两个连续的
reshape操作不一定“取消”退出,可以用最外层的reshape替换(请参阅下面的更多信息)。 - 至于
permute操作,您只需要确定您是否真的需要它们(下面还有更多信息)。
详细答复:
你有很多多余和不必要的步骤。在这里,我已经概述了几个,并提出了一个替代解决方案,无疑会更快。顺便提一句,在不真正了解它们的情况下,在粘贴一堆不同的东西之前,先了解代码并确保您理解了所有的部分,这是非常有益的。
- 您不需要使用逻辑比较
1:end~=2,只需简单地指定除2之外的所有索引 without_column_2 = c(:,1 3:结束) permute(a', [2 1])是完全没有必要的,因为您正在获取某物的复杂共轭转置(使用'),然后立即再次接受转置(这一次使用permute),这将产生原始矩阵。只要用a代替这个就行了。在您的例子中,这只是简单的conj(c(:,[1 3:end]))- 连续两个
reshapes是不必要的。你写它的方式,你先把它重塑成一个行向量,然后取转置线(从技术上说是另一个reshape),使它成为一个列向量,然后重塑成一个3xN。只需跳过前两个步骤,直接走到3xN。 重塑(c(:,1 3:结束),3,[]); 尽管如此,如果您仔细观察这个,您的原始数据已经是这个形状的,因此您不需要进行任何整形。如果您实际上需要复杂的共轭(因为您显然不需要转置部分),您可以使用conj来获得它。
对于那些保持分数的人,这意味着我们现在简化了:
reshape(reshape(permute(c(:,1:end~=2)',[2 1]),1,3*2).', 3, [])至
conj(c(:,[1 3:end]))现在,为了使c的每一列沿着第二个维度,您使用了一个permute;然而,这只是一个简单的reshape操作
reshape(conj(c(:,[1 3:end])), 1, size(c, 1), [])现在,你必须用c(:,1)取外积,然后共轭转置结果。
这将简化为:
out = conj(permute(bsxfun(@mtimes, reshape(conj(c(:,[1 3:end])), 1, size(c, 1), []), c(:,1)), [2 1 3]));然而,在这一切之后,为什么要把它放在一条线上呢?它确实使它非常难以辨认,并且很可能会使任何在您之后查看此代码的人感到困惑。你最好把它分成多行,这样逻辑就更容易理解了。
Stack Overflow用户
发布于 2016-08-26 06:44:42
您问哪个部分最耗时,所以我将讨论如何找出:
我们要做的第一件事是将"1-liner“代码重新排列为以下单个操作(请注意,我显式地将transpose和ctranspose而不是.'和'分别放在了):
function q39156646
c = rand(3)+1i*rand(3); % Changed this slightly to represent the problem better.
A = bsxfun(@mtimes,...
permute(...
reshape(...
transpose(...
reshape(...
permute(...
ctranspose(...
c(:,1:end~=2)...
),...
[2 1]),...
1,3*2)...
),...
3, []),...
[3,1,2]),...
c(:,1));
conj(permute(A,[2 1 3]));然后,我们运行分析器并获得:
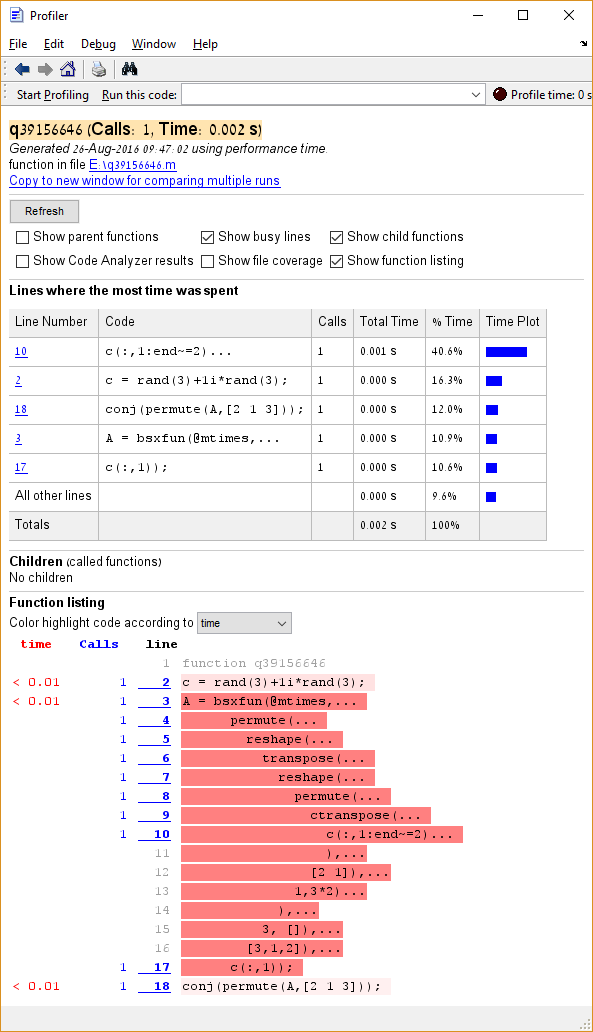
因此:c 占用的时间最多(虽然很难准确地根据百分比(而不是顺序)来判断,由于总体运行时较低,差异很大)。
https://stackoverflow.com/questions/39156646
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号