
使用CSS选择器和Python对表中的多行单元格进行and抓取
使用CSS选择器和Python对表中的多行单元格进行and抓取
提问于 2016-08-24 20:35:50
因此,我在网页上抓取一个页面(http://canoeracing.org.uk/marathon/results/burton2016.htm),其中表中有多行单元格:
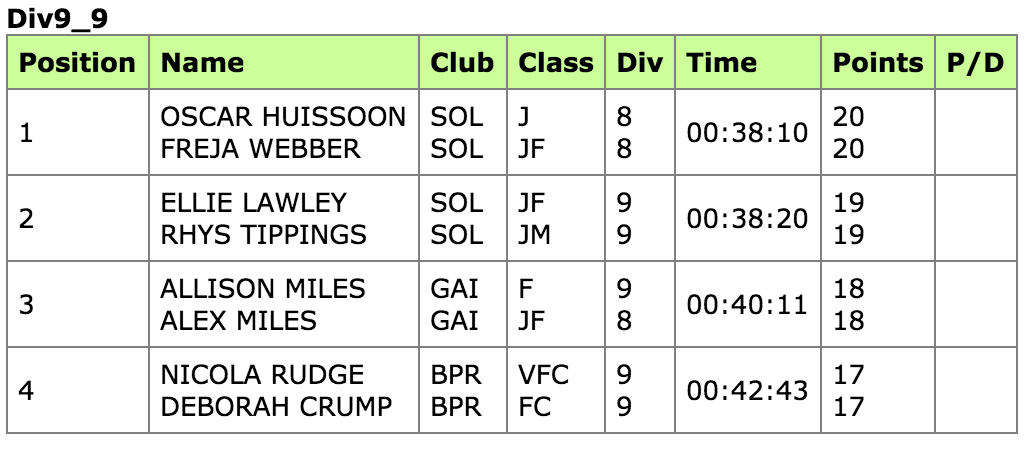
我使用下面的代码来抓取每一列(下面的一列恰好刮掉了名称):
import lxml.html
from lxml.cssselect import CSSSelector
# get some html
import requests
r = requests.get('http://canoeracing.org.uk/marathon/results/burton2016.htm')
# build the DOM Tree
tree = lxml.html.fromstring(r.text)
# construct a CSS Selector
sel1 = CSSSelector('body > table > tr > td:nth-child(2)')
# Apply the selector to the DOM tree.
results1 = sel1(tree)
# get the text out of all the results
data1 = [result.text for result in results1]不幸的是,它只是从每个单元格中返回名称,而不是同时返回两者。我在webscraping工具Kimono上尝试过类似的东西,并且我能够同时抓取这两种工具,但是当Kimono在多个网页上运行时,我想发送Python代码。
回答 1
Stack Overflow用户
回答已采纳
发布于 2016-08-24 20:40:57
问题是,有些单元格包含由<br>分隔的多个文本节点。在这种情况下,查找所有文本节点并加入它们:
data1 = [", ".join(result.xpath("text()")) for result in rows] 对于屏幕截图中提供的行,您将得到:
OSCAR HUISSOON, FREJA WEBBER
ELLIE LAWLEY, RHYS TIPPINGS
ALLISON MILES, ALEX MILES
NICOLA RUDGE, DEBORAH CRUMP您也可以使用.text_content()方法,但是您将失去文本节点之间的分隔符,从而在结果中得到类似于OSCAR HUISSOONFREJA WEBBER的内容。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/39132613
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号