
星星之火没有使用所有配置的内存。
使用Spark-2.1.0快照在10个节点集群上以独立客户端模式启动星火。
9个节点为工作节点,10个节点为主控节点和司机节点。每个256 of的内存。我很难充分利用我的集群。
我正在使用以下参数将执行器和驱动程序的内存限制设置为200 to:
spark-shell --executor-memory 200g --driver-memory 200g --conf spark.driver.maxResultSize=200g当我的应用程序启动时,我可以在控制台和spark /environment/选项卡中看到按预期设置的值。
但是当我转到/executors/选项卡时,我看到我的节点分配的存储内存只有114.3GB,参见下面的屏幕。
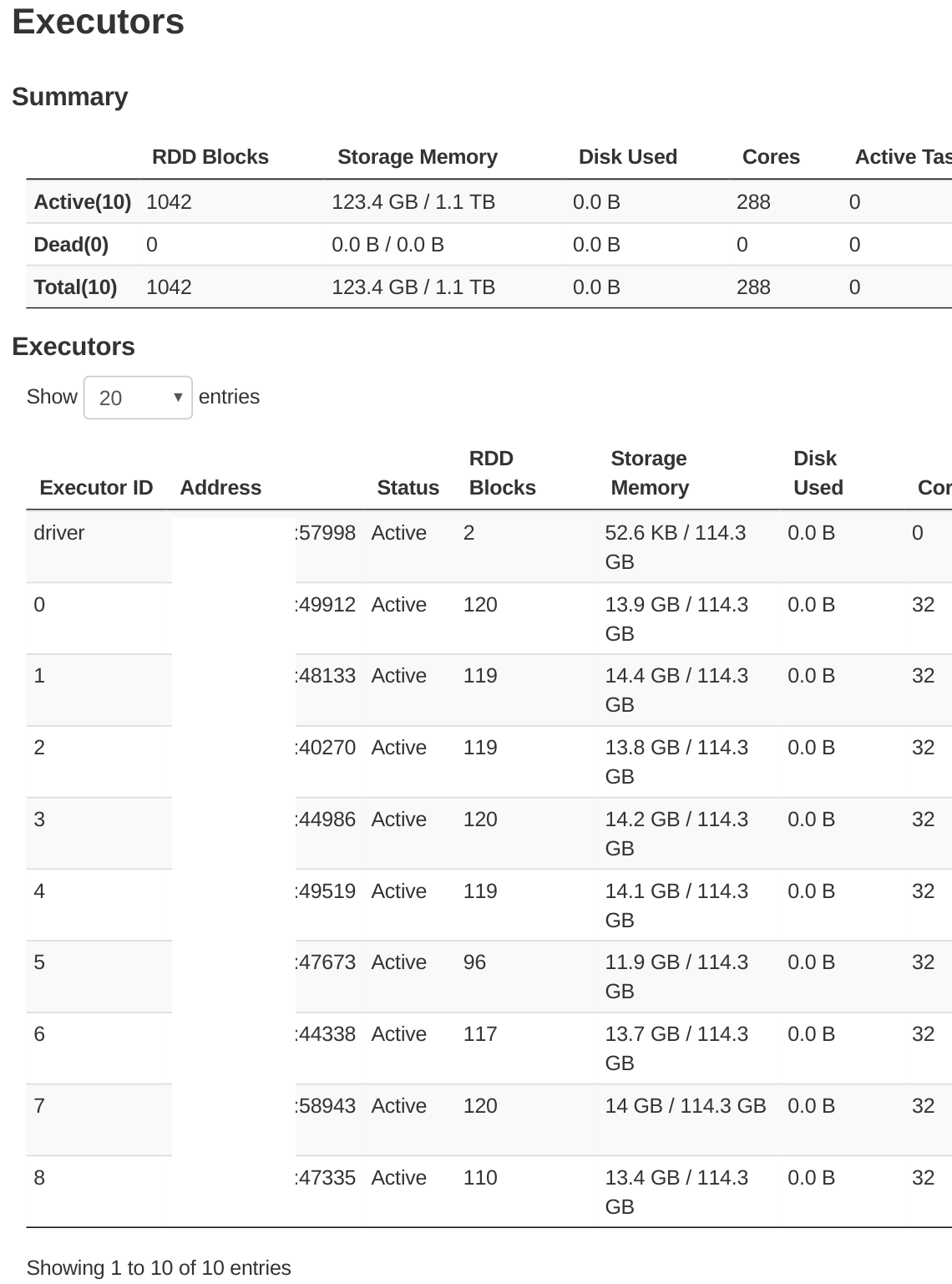
这里显示的总内存是1.1TB,而我希望有2TB。我再次检查了其他进程是否没有使用内存。
你知不知道这种差异的根源是什么?我错过什么环境了吗?它是/executors/选项卡中的一个bug还是火花引擎中的一个bug?
回答 1
Stack Overflow用户
发布于 2016-08-24 17:20:31
您正在充分利用内存,但这里只查看内存的存储部分。默认情况下,存储部分占总内存的60%。
来自星火博士
Spark中的内存使用主要分为两类:执行和存储。执行内存是指在混搭、连接、排序和聚合中用于计算的内存,而存储内存是指用于缓存和在集群中传播内部数据的内存。
从Spark1.6开始,执行内存和存储内存是共享的,因此不需要调优memory.fraction参数。
如果您使用的是纱线,则资源管理器的“内存使用”和“内存总量”的主页将表示内存的总使用量。
https://stackoverflow.com/questions/39128897
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号