
将DataFrame附加到另一个DataFrame (在特定的MultiIndex上)
将DataFrame附加到另一个DataFrame (在特定的MultiIndex上)
提问于 2016-08-18 14:12:46
在下面的DataFrame中,即df1
In[0]: df1
Out[0]:
A B
first second
bar one 1.764052 0.400157
one 0.978738 2.240893
one 1.867558 -0.977278
two 0.950088 -0.151357我希望在MultiIndex ('bar','one')的最后一行之后追加另一个MultiIndex,同时给新添加的行提供相同的MultiIndex。
也就是说,对于下面的df2
In[1]: df2
Out[1]:
A B
first second
baz three -0.103219 0.410599
three 0.144044 1.454274预期的结果是:
A B
first second
bar one 1.764052 0.400157
one 0.978738 2.240893
one 1.867558 -0.977278
one -0.103219 0.410599 # there 2 rows
one 0.144044 1.454274 # arrived from df2
two 0.950088 -0.151357到目前为止,才是问题所在.
我前面的一些尝试都失败了:
(1)按组迭代(使用groupby)并根据df2值连接一个新的DataFrame:
for idx, data in df1.groupby(level=[0,1]):
df1.loc[idx] = pd.concat([data, pd.DataFrame(df2, index=idx)], ignore_index=True)
Exception: cannot handle a non-unique multi-index!(还尝试将它们放置在一个新的DataFrame__中)。
(2) 重编索引 df2优先:
for idx, data in df1.groupby(level=[0,1]):
df2.reindex(idx)
Exception: cannot handle a non-unique multi-index!或者:
for idx, data in df1.groupby(level=[0,1]):
df2.index = idx
break
A B
bar -0.103219 0.410599
one 0.144044 1.454274回答 1
Stack Overflow用户
回答已采纳
发布于 2016-08-18 15:11:23
如果您想要手动将数据插入到现有的dataframe中,则需要决定几件事。
- 你打算把它插入哪里?我通过找到索引为
('bar', 'one')的第一个实例来解决这个问题。 - 你打算怎么称呼这些数据?换句话说,您要插入的数据的索引是什么?显然,您正在更改索引值。您必须提前知道这些索引值是什么。除非您希望它继承紧接它前面的行的索引值(我也会显示这一点)。
position = (df1.index.to_series() == ('bar', 'two')).values.argmax()
pd.concat([
df1.iloc[:position],
df2.set_index([['bar', 'bar'], ['one', 'one']]),
df1.iloc[position:]
])
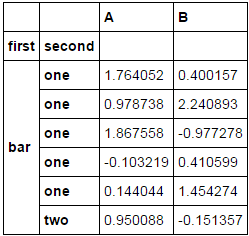
新行从前一行继承索引值的示例(结果与上面相同)
position = (df1.index.to_series() == ('bar', 'two')).values.argmax()
insert_idx = pd.MultiIndex.from_tuples(df1.index[[position - 1]].tolist() * len(df2))
pd.concat([
df1.iloc[:position],
df2.set_index(insert_idx),
df1.iloc[position:]
])页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/39020493
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号