
从非分区表迁移到已分区表
在六月的烧烤队宣布对日期分区表的支持。但是,指南缺少如何将旧的非分区表迁移到新样式中。
我正在寻找一种方法,以更新几个,如果不是所有的表,以新的风格。
此外,在日类型分区之外,还有哪些其他选项可用?有没有烧烤UI显示这一点,因为我无法创建这样一个新的分区表从烧烤网络UI。
回答 5
Stack Overflow用户
发布于 2017-03-31 01:38:00
从Pavan的回答:请注意,这种方法将收取您的扫描成本的源表的查询次数与您的查询。
来自Pentium10的评论:假设我有几年的数据,我需要为每一天准备不同的查询并运行所有的数据,如果我有1000天的历史,我需要支付1000倍于源表的完整查询价格?
正如我们所看到的-这里的主要问题是对每一天进行全面扫描。其余的问题较少,可以轻松地在任何选择的客户中编写脚本。
因此,下面是to -如何划分表,同时避免每天对表进行完整的扫描?
下面一步一步地展示了该方法。
它具有足够的通用性,可以扩展/应用于任何实际用例--同时,我使用的是bigquery-public-data.noaa_gsod.gsod2017,并且我将“练习”限制在仅10天内,以保持它的可读性。
步骤1 -创建数据透视表
在这一步中,我们
a)将每一行的内容压缩为记录/数组
和
( b)把它们都放在各自的“每日”专栏中
#standardSQL
SELECT
ARRAY_CONCAT_AGG(CASE WHEN d = 'day20170101' THEN r END) AS day20170101,
ARRAY_CONCAT_AGG(CASE WHEN d = 'day20170102' THEN r END) AS day20170102,
ARRAY_CONCAT_AGG(CASE WHEN d = 'day20170103' THEN r END) AS day20170103,
ARRAY_CONCAT_AGG(CASE WHEN d = 'day20170104' THEN r END) AS day20170104,
ARRAY_CONCAT_AGG(CASE WHEN d = 'day20170105' THEN r END) AS day20170105,
ARRAY_CONCAT_AGG(CASE WHEN d = 'day20170106' THEN r END) AS day20170106,
ARRAY_CONCAT_AGG(CASE WHEN d = 'day20170107' THEN r END) AS day20170107,
ARRAY_CONCAT_AGG(CASE WHEN d = 'day20170108' THEN r END) AS day20170108,
ARRAY_CONCAT_AGG(CASE WHEN d = 'day20170109' THEN r END) AS day20170109,
ARRAY_CONCAT_AGG(CASE WHEN d = 'day20170110' THEN r END) AS day20170110
FROM (
SELECT d, r, ROW_NUMBER() OVER(PARTITION BY d) AS line
FROM (
SELECT
stn, CONCAT('day', year, mo, da) AS d, ARRAY_AGG(t) AS r
FROM `bigquery-public-data.noaa_gsod.gsod2017` AS t
GROUP BY stn, d
)
)
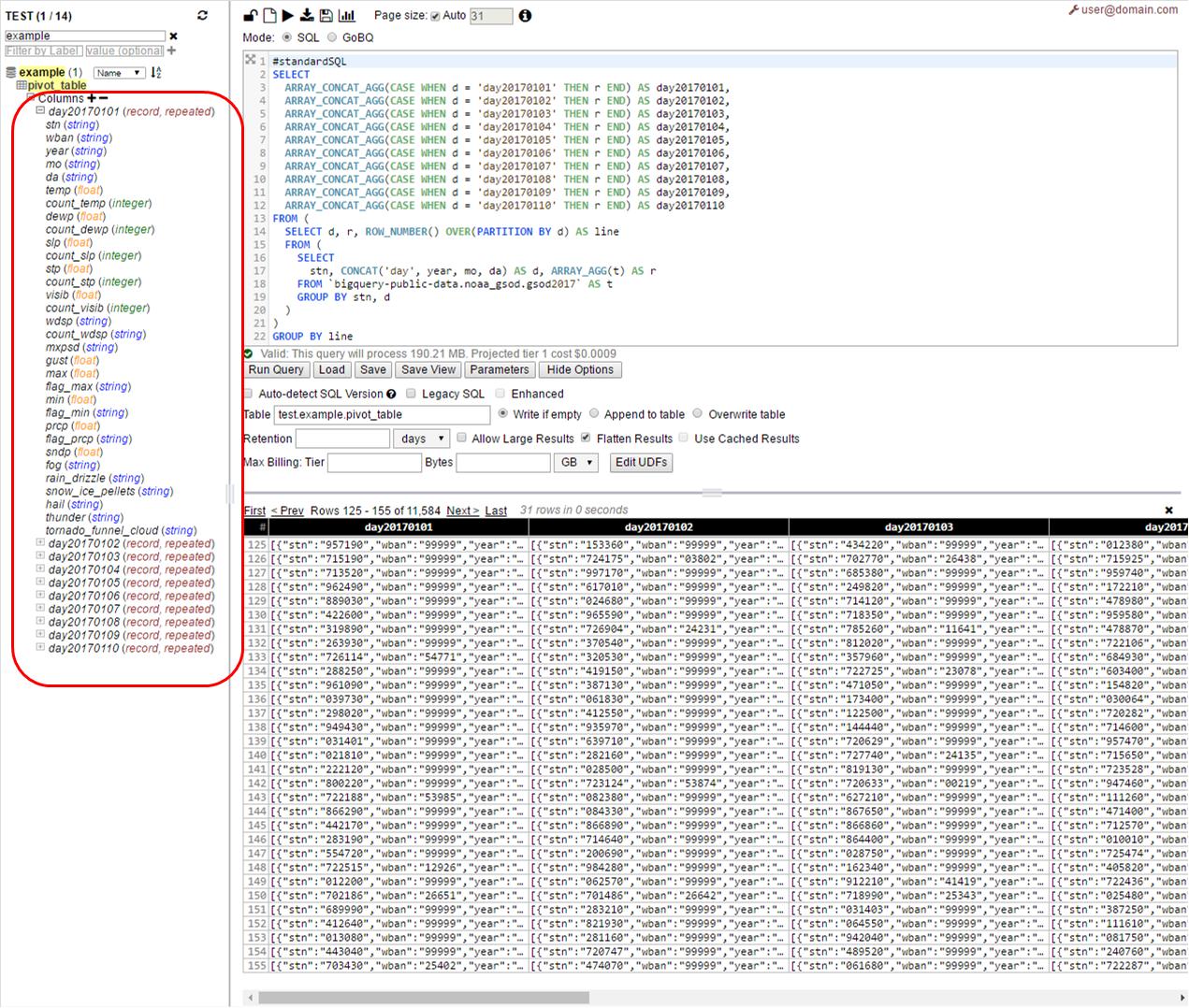
GROUP BY line 以pivot_table (或其他首选名称)为目标,在Web中运行上述查询
如我们所见-在这里我们将得到10列的表-一天一列,每列的模式是原始表的模式的副本:
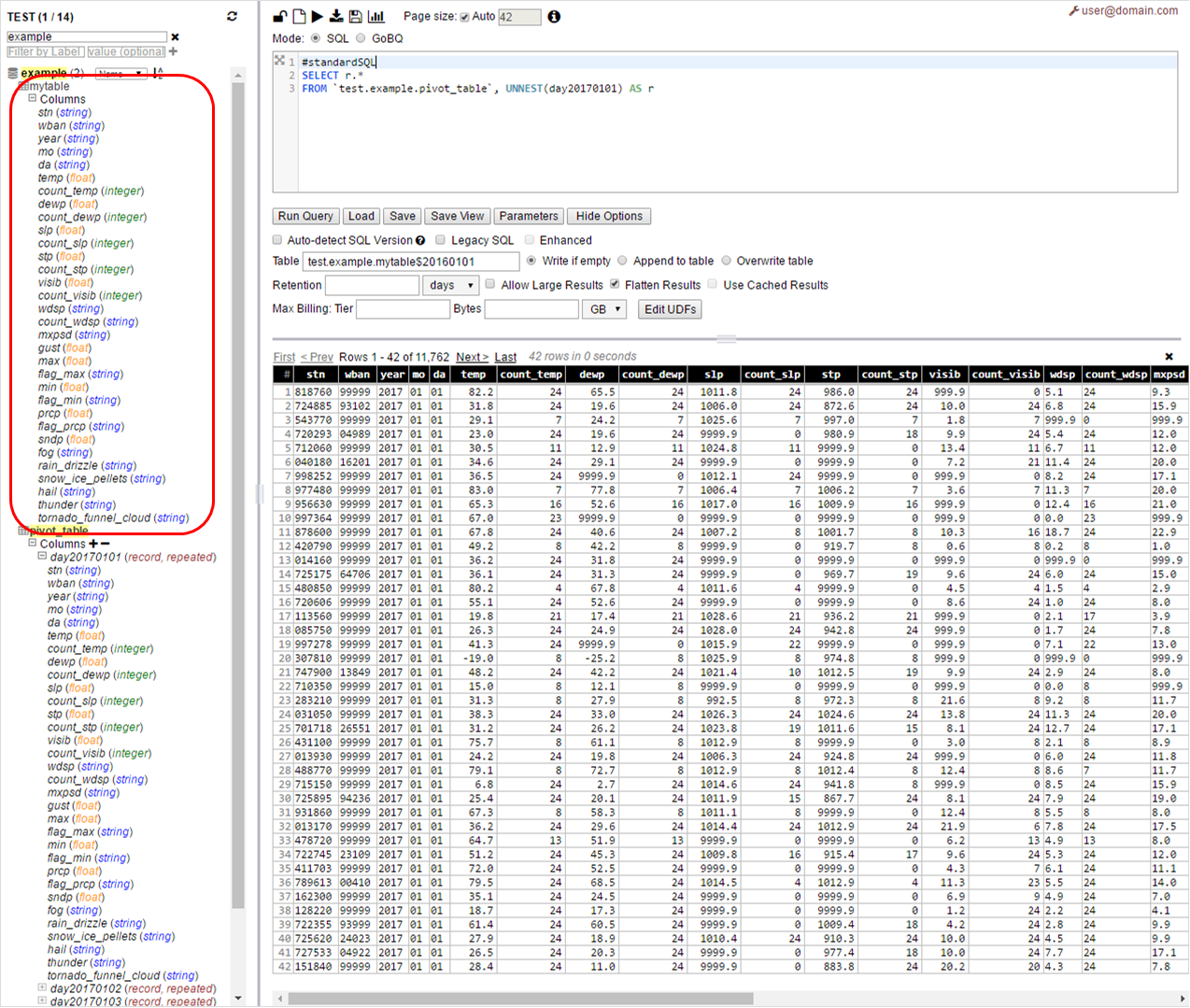
步骤2 -处理分区只逐个扫描各自的列(没有完整的表扫描)-插入到各自的分区中
#standardSQL
SELECT r.*
FROM pivot_table, UNNEST(day20170101) AS r使用名为mytable$20160101的目标表从Web运行上述查询
第二天你也可以跑同样的路
#standardSQL
SELECT r.*
FROM pivot_table, UNNEST(day20170102) AS r现在您应该有目标表,如mytable,$20160102等等。
您应该能够使用您选择的任何客户端自动/编写此步骤。
有许多不同的方法,你可以使用上述方法-这取决于你的创造力。
注意: BigQuery允许表中最多有10000列,因此在一年的每一天中,365列绝对不是一个问题:o)除非对使用新分区的时间有限制--我听说(但还没有机会检查)--现在已经不超过90天了。
更新
请注意:上面的版本有一个额外的逻辑,将所有聚合的单元格封装到尽可能少的最后行数中。
ROW_NUMBER() OVER(PARTITION BY d) AS line
然后
GROUP BY line
随同
ARRAY_CONCAT_AGG(…)
这样做吗?
当原始表中的行大小不太大时,这是很好的,因此最终的合并行大小仍将在BigQuery的行大小限制内(我相信到目前为止,这个限制是10 MB )。
如果源表的行大小已接近此限制-请使用低于调整后的版本。
在此版本中,将删除分组,使每一行只有一个列的值。
#standardSQL
SELECT
CASE WHEN d = 'day20170101' THEN r END AS day20170101,
CASE WHEN d = 'day20170102' THEN r END AS day20170102,
CASE WHEN d = 'day20170103' THEN r END AS day20170103,
CASE WHEN d = 'day20170104' THEN r END AS day20170104,
CASE WHEN d = 'day20170105' THEN r END AS day20170105,
CASE WHEN d = 'day20170106' THEN r END AS day20170106,
CASE WHEN d = 'day20170107' THEN r END AS day20170107,
CASE WHEN d = 'day20170108' THEN r END AS day20170108,
CASE WHEN d = 'day20170109' THEN r END AS day20170109,
CASE WHEN d = 'day20170110' THEN r END AS day20170110
FROM (
SELECT
stn, CONCAT('day', year, mo, da) AS d, ARRAY_AGG(t) AS r
FROM `bigquery-public-data.noaa_gsod.gsod2017` AS t
GROUP BY stn, d
)
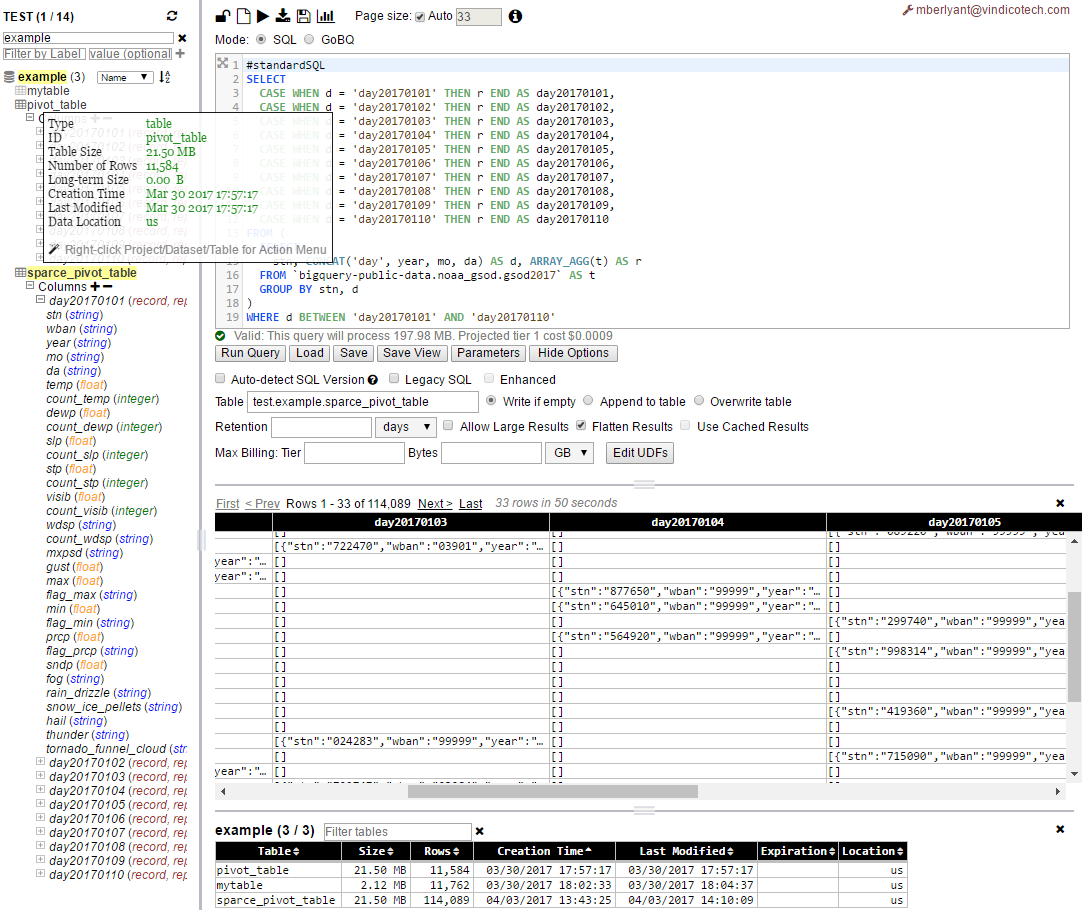
WHERE d BETWEEN 'day20170101' AND 'day20170110'正如您所看到的,现在-枢轴表(sparce_pivot_table)足够稀疏(相同的21.5MB,但现在在pivot_table中有114,089行和11,584行),因此它的平均行大小在初始版本为190 B和1.9KB。这显然比示例中的每列数少10倍。
因此,在使用这种方法之前,需要做一些数学来预测/估计可以做什么和如何做!
不过: pivot表中的每个单元格都是原始表中整行的JSON表示形式。因为它不仅保存原始表中的行的值,而且在其中包含一个模式。
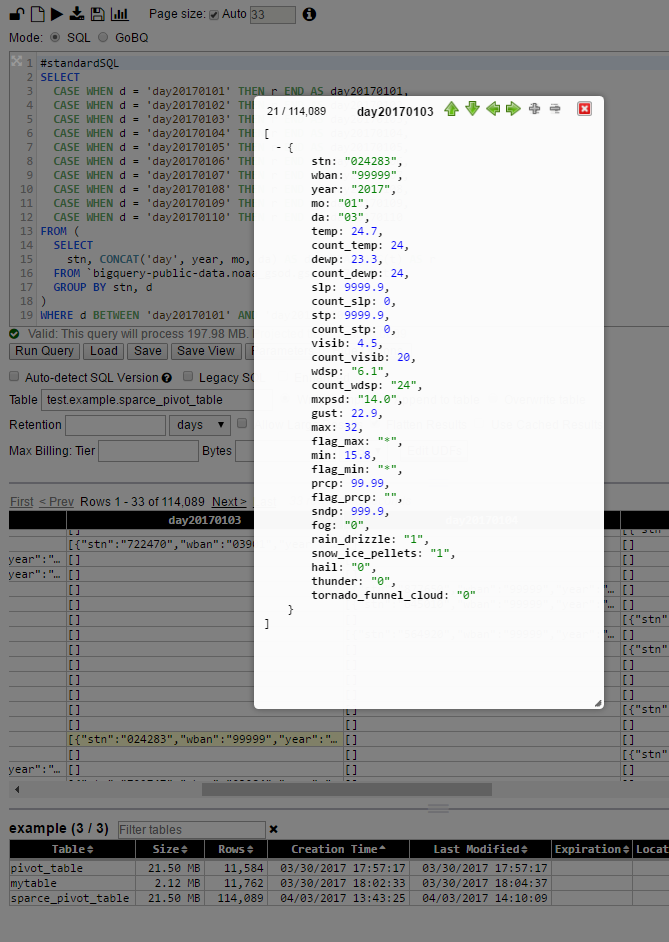
因此,它非常冗长--因此单元格的大小可以是原始大小的多倍,这限制了这种方法的使用.除非你变得更有创意:不).这里仍然有很多地方需要应用:o)
Stack Overflow用户
发布于 2019-04-25 16:23:04
适用于我的是以下直接应用于大查询中的查询集(大查询创建新查询)。
CREATE TABLE (new?)dataset.new_table PARTITION BY DATE(date_column) AS SELECT * FROM dataset.table_to_copy;
然后,作为下一步,我删除了表:
DROP TABLE dataset.table_to_copy;
我只使用步骤2从https://fivetran.com/docs/warehouses/bigquery/partition-table获得了这个解决方案
Stack Overflow用户
发布于 2018-02-09 09:57:54
现在,您可以通过查询非分区表并指定分区列,从非分区表创建分区表。您将为原始(非分区)表上的一次全表扫描支付费用。Note:这是目前的测试版。
若要从查询结果创建分区表,请将结果写入新的目标表。您可以通过查询分区表或非分区表来创建已分区表。不能使用查询结果将现有标准表更改为已分区表。
https://stackoverflow.com/questions/38993877
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号