
按嵌套字典键分组熊猫数据
按嵌套字典键分组熊猫数据
提问于 2016-08-10 19:08:41
我有一个熊猫资料栏,其中一个列是字典类型。这是一个示例dataframe:
import pandas as pd
df = pd.DataFrame({'a': [1,2,3],
'b': [4,5,6],
'version': [{'major': 7, 'minor':1},
{'major':8, 'minor': 5},
{'major':7, 'minor':2}] })df:
a b version
0 1 4 {'minor': 1, 'major': 7}
1 2 5 {'minor': 5, 'major': 8}
2 3 6 {'minor': 2, 'major': 7}我正在寻找一种按字典键对数据进行分组的方法;在本例中,将df数据按version标签中的主键分组。
我尝试过几种不同的东西,从传递字典键到dataframe函数`df.groupby('version') (因为 part 不是dataframe标签的一部分),再到将版本分配给dataframe索引,但是到目前为止还没有起作用。我还试图将字典作为dataframe本身中的附加列来处理,但这似乎有它自己的问题。
有什么想法吗?
抱歉,格式化了,这是我的第一个堆栈溢出问题。
回答 2
Stack Overflow用户
回答已采纳
发布于 2016-08-10 19:11:53
选项1
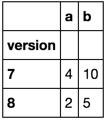
df.groupby(df.version.apply(lambda x: x['major'])).size()
version
7 2
8 1
dtype: int64df.groupby(df.version.apply(lambda x: x['major']))[['a', 'b']].sum()
选项2
df.groupby(df.version.apply(pd.Series).major).size()
major
7 2
8 1
dtype: int64df.groupby(df.version.apply(pd.Series).major)[['a', 'b']].sum()
Stack Overflow用户
发布于 2016-08-10 19:13:00
你可以这样做:
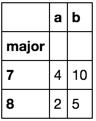
In [15]: df.assign(major=df.version.apply(pd.Series).major).groupby('major').sum()
Out[15]:
a b
major
7 4 10
8 2 5页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/38881679
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号