
概率密度曲线下的面积不等于1
我的模型基于以下增长函数: x_t+1 = x_t +r* x_t *(1-x_t/K)--增长率r是通过随机抽签(mean=0.2,标准deviation=0.2)定义的。我在看股票的概率密度函数,在70年后运行10000次。当我计算概率密度函数下的面积时,当标准差为0.1时,它大致等于1,但对于0.2或0.3的标准差,则不等于1。我为区域A创建了一个有100个值的直方图。它在A=2上显示出一个很高的峰值,但是面积的值甚至上升到8,为什么它不等于1?
runs=10000
mean=0.2
sd=0.2
K=1
x_0=0.4
v=0.1
t=70
y=c()
x=x_0
for (j in 1:runs) {
rand=rnorm(t,mean,sd)
for (i in 1:t) {
x=max(x+rand[i]*x*(x-v)*(1-x/K),0)
if(i==t)
y[j]=x
next}
x=x_0
next }
library(sfsmisc)
Dens=density(y)
f=approxfun(Dens$x, Dens$y)
h=c()
i=seq(0.9, 1, length.out=100000)
for (e in 1:length(i)) {
h[e]=f(i[e])
next}
options(max.print=1000000)
h[is.na(h)]=0
area=sum(abs(h[-1]+h[-length(h)])/2*diff(i))谢谢!
回答 1
Stack Overflow用户
发布于 2016-08-01 16:12:16
你的数值积分有很大的缺陷。
首先,这是一个密度的地块:
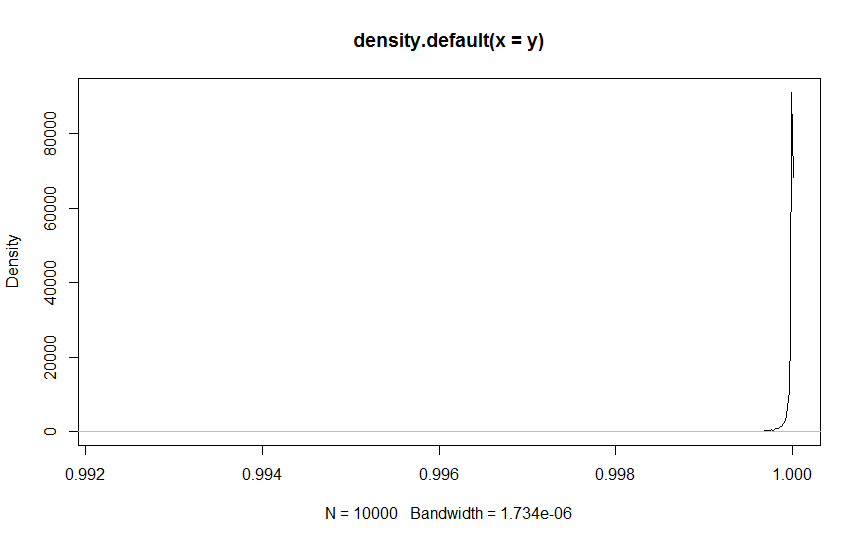
几乎所有的区域都在一个非常狭窄的高度尖峰下面。你的绝大多数样本点都在那个峰值之外,所以在估计这个峰值的面积方面做得不太好。
如果您评估print(Dens),您会看到以下内容:
Call:
density.default(x = y)
Data: y (10000 obs.); Bandwidth 'bw' = 1.734e-06
x y
Min. :0.9922 Min. : 0.0
1st Qu.:0.9942 1st Qu.: 0.0
Median :0.9961 Median : 0.0
Mean :0.9961 Mean : 439.1
3rd Qu.:0.9981 3rd Qu.: 0.0
Max. :1.0000 Max. :91131.2 特别要注意的是,x值都> 0.99,但是在区间.9,1上使用的是数值积分,因此,大多数数值积分都超出了密度的范围。您正在使用(通过approxfun)在0.9、0.99范围内的外推值,并将数据的范围(相对地说)外推。因此,90%的数值积分是基于两个几乎为零的值的不可靠外推法(前两个y值)。
你需要找到某种方法来恢复数据。对density本身的调用是有问题的。它使用512点(作为缺省值),但是如果你看一下它们,只有几十个y值明显大于0。您正试图通过对尾部进行抽样而不是对正在发生重大事件的值进行抽样来获得分布的图片。
https://stackoverflow.com/questions/38697776
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号