
聚类均匀度分析及RapidMiner中簇距离性能算子的应用
聚类均匀度分析及RapidMiner中簇距离性能算子的应用
提问于 2016-07-27 06:00:09
我已经在数据集上实现了k-均值聚类。我尝试通过查看快速采煤机中的平行图和偏差图来分析聚类的k。
为了分析各种性能模型的clusters.Out的同质性,将算子“集群距离性能”算子用于k-均值聚类结果。
- 是否有其他经营者可以提供这方面的分析?
- 我所拥有的数据集有具有大值的数字向量(以数百和千为单位),还有一个具有极小值的数据集(十进制的第5位至第8位)。
我不知道如何解释操作符“集群距离性能”的结果,如下所示
质心表结果
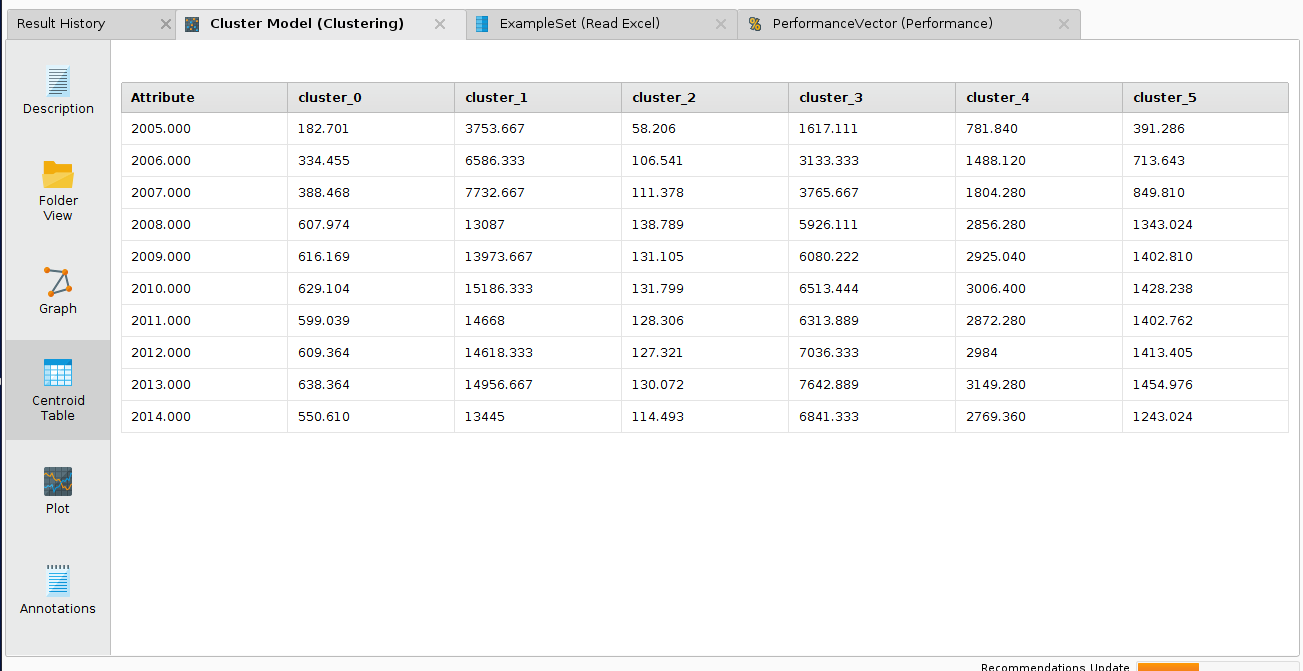
而性能向量算子的结果是
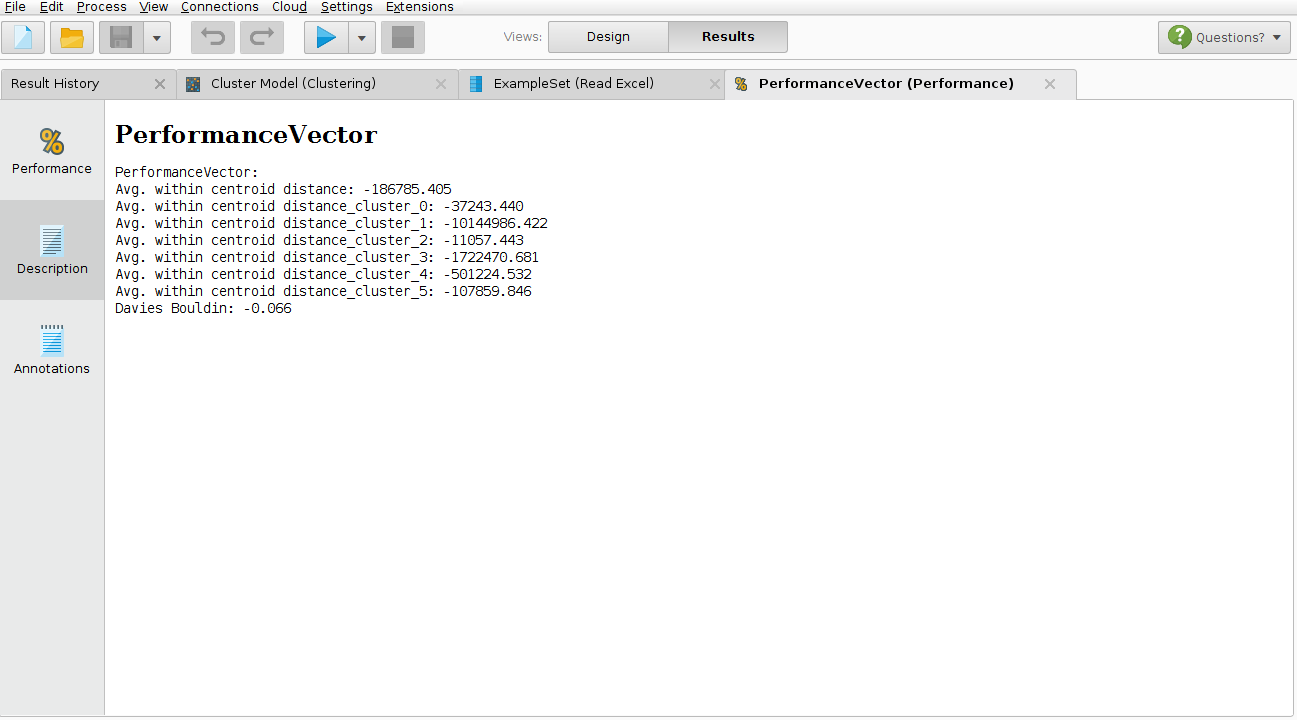
有人能帮我吗?虽然我读到越小,Davies的值越小,更好的是聚类。
回答 2
Stack Overflow用户
发布于 2016-07-27 12:00:58
如果您试图找到“最佳”聚类,那么您必须更改k并计算不同的聚类有效性度量,以比较它们在k变化时的变化。戴维斯-博尔丁通常是一个很好的人,因为“最好”的信号是最低限度的。“最佳”的定义是从用于构建有效性度量的数学技术(基于合理和逻辑的技术)的角度出发,但是一个人总是必须看聚类来确定结果是否具有实际意义。
Stack Overflow用户
发布于 2022-03-20 02:42:16
您应该查看其他性能指标,因为只应用一个可以防止您看到全局。添加安德鲁提到的内容:
- Calinski-Harabasz得分
- 剪影评分
- 弯头法
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/38604841
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号