
学习支持向量机数字识别
我想制作一个程序来识别图像中的数字。我遵循科学知识学习中的教程。
我可以训练和安装svm分类器,如下所示。
首先,导入库和数据集。
from sklearn import datasets, svm, metrics
digits = datasets.load_digits()
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))其次,建立支持向量机模型,并利用数据集对其进行训练。
classifier = svm.SVC(gamma = 0.001)
classifier.fit(data[:n_samples], digits.target[:n_samples])然后,我试着读取自己的图像,并使用函数predict()来识别数字。
这是我的形象:

I将图像整形为(8,8),然后将其转换为1D数组.。
img = misc.imread("w1.jpg")
img = misc.imresize(img, (8, 8))
img = img[:, :, 0]最后,当我打印出预测时,它返回1
predicted = classifier.predict(img.reshape((1,img.shape[0]*img.shape[1] )))
print predicted无论我使用其他图像,它仍然返回1。


当我打印数字"9“的"default”dataset时,它看起来如下:
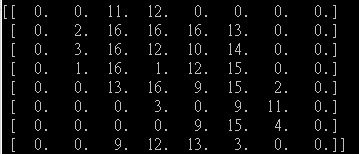
我的图像号码"9“:
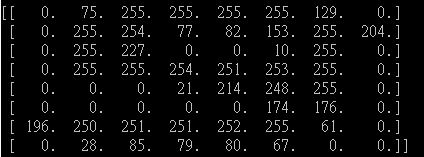
你可以看到,对于我的图像来说,非零的数字是相当大的。
我不知道为什么。我正在寻求帮助来解决我的问题。谢谢
回答 7
Stack Overflow用户
发布于 2016-07-25 20:32:44
我最好的选择是,您的数据类型和数组形状存在问题。
看起来,您正在对np.float64类型的numpy数组进行培训(或者在32位系统上可能是np.float32,我不记得了),并且每个图像的形状都是(64,)。
同时,在代码中调整大小操作之后,用于预测的输入图像是uint8和shape (1, 64)类型。
我首先尝试更改输入图像的形状,因为dtype转换通常就像您预期的那样工作。因此,请更改这一行:
predicted = classifier.predict(img.reshape((1,img.shape[0]*img.shape[1] )))
对此:
predicted = classifier.predict(img.reshape(img.shape[0]*img.shape[1]))
如果这不能修复它,则始终可以尝试重铸数据类型。
img = img.astype(digits.images.dtype)。
我希望这能帮上忙。通过代理进行调试比实际坐在计算机前要困难得多:)
编辑:根据SciPy文档,培训数据包含从0到16的整数值。输入图像中的值应该缩放以适应相同的间隔。(位数)
Stack Overflow用户
发布于 2016-07-27 10:49:08
1)你需要建立你自己的训练集--基于与你所做的预测相似的数据。在scikit-learn中对datasets.load_digits()的调用是加载MNIST数字数据集的预处理版本,据我们所知,该数据集的图像可能与您试图识别的图像非常不同。
2)正确设置分类器的参数。对svm.SVC(gamma = 0.001)的调用只是在SVC中选择γ参数的任意值,这可能不是最佳选择。此外,您没有配置C参数--这对于SVMs非常重要。我敢打赌,这就是为什么你的输出“总是1”的原因之一。
3)无论您为您的模型选择何种最终设置,您都需要使用交叉验证方案,以确保该算法有效地学习。
这背后有很多机器学习理论,但是,作为一个良好的开端,我建议您看看支持向量机-科学-学习,以便更深入地描述SVC在镰状体学习中的实现是如何工作的,而GridSearchCV则是一种简单的参数设置技术。
Stack Overflow用户
发布于 2016-07-22 07:59:01
这只是猜测但是..。来自Sk的培训集是黑色数字在白色背景上。你在试图预测黑色背景下白色的数字.
我认为你要么应该在你的训练集上训练,要么训练你的照片的负面版本。
我希望这能帮上忙!
https://stackoverflow.com/questions/38519716
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号